如何从处理器和加速器内核中榨取最大性能?
一些设计团队在创建片上系统(SoC)设备时,有幸能够使用最新和最先进的技术节点,并且拥有相对不受限制的预算来从可信的第三方供应商那里获取知识产权(IP)模块。然而,许多工程师并没有这么幸运。对于每一个「不惜一切代价」的项目,都有一千个「在有限预算下尽你所能」的对应项目。
一种从成本较低、早期代、中档处理器和加速器核心中挤出最大性能的方法是,明智地应用缓存。
削减成本
图 1 展示了一个典型的成本意识 SoC 场景的简化示例。尽管 SoC 可能由许多 IP 组成,但这里为了清晰起见,只展示了三个。
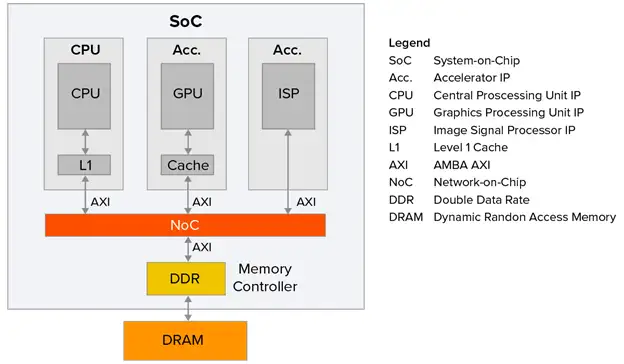
图 1SoC 内部 IP 之间连接的主要技术是网络片上(NoC)互连 IP。这可以被看作是一个跨越整个设备的 IP。图 1 中展示的例子可以假定为一个非缓存一致性场景。在这种情况下,任何一致性需求将由软件处理
假设 SoC 的时钟运行在 1GHz。假设一个基于精简指令集计算机(RISC)架构的中央处理单元(CPU)运行一个典型指令将消耗一个时钟周期。然而,访问外部 DRAM 内存可能需要 100 到 200 个处理器时钟周期(为了本文的目的,我们将这个平均为 150 个周期)。这意味着,如果 CPU 没有一级(L1)缓存,并且通过 NoC 和 DDR 内存控制器直接连接到 DRAM,那么每个指令将消耗 150 个处理器时钟周期,导致 CPU 利用率仅为 1/150 = 0.67%。
这就是为什么 CPU 以及一些加速器和其他 IP 使用缓存内存来提高处理器利用率和应用程序性能。缓存概念基于的基本原理是局部性原则。这个观点是,在任何给定时间,只有一小部分主内存被使用,而且那个空间中的位置被多次访问。主要是由于循环、嵌套循环和子程序,指令及其相关数据经历时间、空间和顺序局部性。这意味着,一旦一块指令和数据从主内存复制到 IP 的缓存中,IP 通常会反复访问它们。
当今高端 CPU IP 通常至少有一个一级(L1)和二级(L2)缓存,它们通常还有一个三级(L3)缓存。此外,一些加速器 IP,如图形处理单元(GPU)通常有自己的内部缓存。然而,这些最新一代的高端 IP 的价格通常比上一代中档产品高出 5 倍到 10 倍。因此,正如图 1 所示,一个注重成本的 SoC 中的 CPU 可能只配备了一个 L1 缓存。
更深入地考虑 CPU 及其 L1 缓存。当 CPU 在其缓存中请求某物时,结果被称为缓存命中。由于 L1 缓存通常以与处理器核心相同的速度运行,因此缓存命中将在单个处理器时钟周期内处理。相比之下,如果请求的数据不在缓存中,结果称为缓存未命中,将需要访问主内存,这将消耗 150 个处理器时钟周期。
现在考虑运行 1,000,000 条指令。如果缓存足够大以包含整个程序,那么这将只消耗 1,000,000 个时钟周期,从而实现 100% 的 CPU 效率。
不幸的是,中档 CPU 中的 L1 缓存通常只有 16KB 到 64KB 的大小。如果我们假设 95% 的缓存命中率,那么我们的 1,000,000 条指令中的 950,000 条将需要一个处理器时钟周期。其余的 50,000 条指令每条将消耗 150 个时钟周期。因此,这种情况下的 CPU 效率可以计算为 1,000,000/((950,000 * 1) + (50,000 * 150)) = ~12%。
提升性能
提高注重成本 SoC 性能的一种成本效益高的方式是添加缓存 IP。例如,Arteris 的 CodaCache 是一个可配置的、独立的非一致性缓存 IP。每个 CodaCache 实例可以高达 8MB,并且可以在同一个 SoC 中实例化多个副本,如图 2 所示。
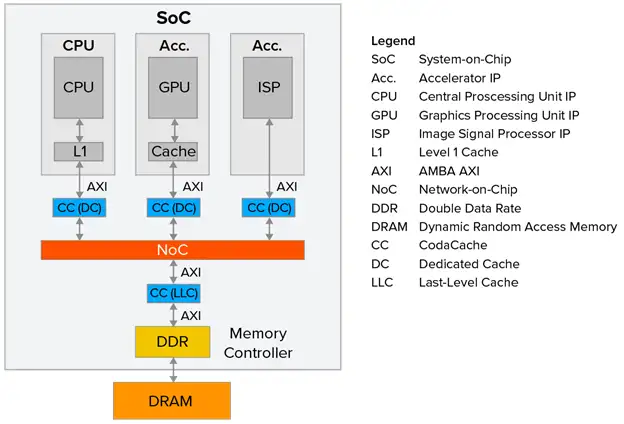
图 2本文的目的并不是建议每个 IP 都应该配备一个 CodaCache。图 2 仅旨在提供潜在 CodaCache 部署的示例。
如果一个 CodaCache 实例与一个 IP 关联,它被称为专用缓存(DC)。或者,如果一个 CodaCache 实例与一个 DDR 内存控制器关联,它被称为末级缓存(LLC)。DC 将加速与其关联的 IP 的性能,而 LLC 将增强整个 SoC 的性能。
作为我们可能期望的性能提升类型的一个示例,考虑图 2 中显示的 CPU。让我们假设与这个 IP 关联的 CodaCache DC 实例以处理器速度的一半运行,并且对这个缓存的任何访问消耗 20 个处理器时钟周期。如果我们还假设这个 DC 有 95% 的缓存命中率,那么对于 1,000,000 条指令——我们的整体 CPU+L1+DC 效率可以计算为 1,000,000/((950,000 * 1) + (47,500 * 20) + (2,500 * 150)) = ~44%。这是一个~273% 的性能提升!
结论
过去,嵌入式程序员喜欢挑战,尽可能从时钟速度低、内存资源有限的小处理器中挤出最高性能。事实上,计算机杂志通常会向读者提出挑战,例如:「谁能在处理器 Y 上使用最少的时钟周期和最小的内存量执行任务 X?」
今天,许多 SoC 开发者喜欢挑战,尽可能从他们的设计中挤出最高性能,特别是如果他们被限制使用性能较低的中档 IP。部署 CodaCache IP 作为专用和末级缓存,为工程师提供了一种负担得起的方式来提升他们注重成本的 SoC 的性能。
关键词: SoC

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码