芯片大佬领衔,攻英伟达漏洞
最近,芯片界传奇人物、处理器设计大佬、Tenstorrent 现任首席执行官吉姆·凯勒(Jim Keller)在接受采访时表示,英伟达没有很好地服务于很多市场,因此,Tenstorrent 和其它新创 AI 处理器研发公司是有机会的。
Jim Keller 曾任职于多家大牌企业,包括 AMD,英特尔、苹果和特斯拉。1998~1999 年,Jim Keller 在 AMD 主导了支撑速龙系列处理器的 K7/K8 架构开发工作,2008~2012 年,在苹果牵头研发了 A4、A5 处理器,2012~2015 年,在 AMD 主持 K12 Arm 项目和 Zen 架构项目,2016~2018 年,在特斯拉研发 FSD 自动驾驶芯片,2018~2020 年,在英特尔参与了神秘项目。
现在,Jim Keller 在 Tenstorrent 领导 AI 处理器的开发,可以为英伟达昂贵的 GPU 提供价格合理的替代品,英伟达的 GPU 每个售价 20,000 ~ 30,000 美元或更多,Tenstorrent 称,其 Galaxy 系统的效率是英伟达 DGX 的 3 倍,成本低 33%。做高性能 AI 应用处理器的产品替代是 Tenstorrent 工作的一部分,但不是全部,该公司的业务宗旨是服务英伟达未能解决的市场痛点,尤其是在边缘计算领域。
边缘计算 AI 地位提升
随着海量数据持续增加,以及对计算和存储系统实时性和安全性要求的提升,数据中心已经不能满足市场和客户的需求,市场要求相关软硬件系统提供商找到更快捷的方式来服务客户,以提高运营效率并降低成本。在边缘运行 AI 工作负载的边缘到云解决方案有助于满足这一需求,将算力放在靠近数据创建点的网络边缘,对于要求近乎实时的应用至关重要,在本地设备上处理算法和数据等,而不是将这些工作负载传送到云或数据中心。
随着 5G 和物联网的发展,AI 芯片在边缘运算领域的应用前景十分广阔,例如,自动驾驶汽车、智慧城市等场景,都需要在终端装置上进行实时的 AI 推理。为此,多家厂商纷纷推出了专用于边缘推理的 AI 芯片。
在制造业,本地运行的 AI 模型可以快速响应来自传感器和摄像头的数据,以执行重要任务。例如,汽车制造商使用计算机视觉扫描装配线,以在车辆离开工厂之前识别车辆的潜在缺陷。在这样的应用中,非常低的延迟和始终在线的要求使得在整个网络中来回传送数据变得不切实际。即使是少量的延迟也会影响产品质量。另外,低功耗设备无法处理大的 AI 工作负载,例如训练计算机视觉系统所依赖的模型。从边缘到云的整体解决方案结合了两端的优势,后端云为复杂的 AI 工作负载提供可扩展性和处理能力,前端边缘设备将数据和分析紧密地结合在一起,以最大限度地减少延迟。
以 Arduino 低功耗边缘设备为例,许多这类设备的成本不到 100 美元,用户可以组合运行机器学习模型的几台或数千台设备。例如,一家农业企业使用 Arduino 解决方案来最大限度地提高作物产量,方案涉及传感器,这些传感器为边缘设备提供土壤湿度和风况等数据,以确定作物所需的水量。该技术可以帮助农民避免过度浇水,并降低电动水泵的运行成本。
再例如,一家依赖精密车床的制造商将传感器与 Arduino 设备结合使用,以检测异常情况,如微小的振动,这些振动预示着设备很可能出现问题。对于企业来说,定期维护比遇到导致生产停止的意外故障更具成本效益。
以上这些应用显示出边缘计算的价值和作用,从目前的应用发展情况来看,这样的应用需求越来越多,对智能化控制的需求也在增加,这就是边缘 AI 的价值所在。而像英伟达这样的企业,其 GPU 等高性能芯片主要关注的是云计算和数据中心市场的 AI 服务器,对边缘 AI 市场很少关注。基于此,Tenstorrent 等 AI 芯片公司就有机会了。
更多 AI 芯片公司挑战英伟达
随着各路玩家竞相投入,AI 芯片市场呈现百家争鸣之势。据统计,2019 年全球 AI 芯片新创公司数量就已经超过 80 家,总融资额超过 35 亿美元。研究机构预估,到 2025 年,ASIC 将在 AI 芯片市场中占据 43% 的比重,GPU 占 29%,FPGA 占 19%,CPU 占 9%。
一批 AI 芯片新创公司正在崛起,前文提到的 Tenstorrent 就是典型代表;Cerebras Systems 则打造了有史以来最大的芯片 WSE(Wafer Scale Engine),搭载了 1.2 兆个晶体管,让 AI 运算达到了前所未有的规模;明星公司 Groq 则由前 Google 工程师创立,专注于打造用于 AI 推理的低功耗处理器。
这里要介绍一下 Tenstorrent 的技术和产品,它特别看重低功耗,更适合边缘 AI 应用。据日经新闻报道,Tenstorrent 有望在 2024 年底发布其第二代多用途 AI 处理器,但没有透露处理器的名称。根据该公司 2023 年秋天发布的路线图,打算发布其 Black Hole 独立 AI 处理器和 Quasar 低功耗、低成本芯片。
早些年,但担任 Tenstorrent 公司 CTO 的时候,Jim Keller 就很看好低功耗的 RISC-V 架构,其团队基于此自研了 Ascalon CPU。据悉,该公司的新一代 Black Hole AI 芯片是基于 SiFive 的 X280 RISC-V 核设计开发的。
Tenstorrent 表示,即将推出的处理器之所以具有高效率和更低的成本,很重要的一个原因是避免使用高带宽内存(HBM),改用了 GDDR6,这对于为 AI 推理设计的入门级 AI 处理器来说是很匹配的。也就是说,该公司的 AI 芯片架构对内存带宽的消耗低于竞争对手,因此成本较低。
虽然 Tenstorrent 尚未抢占 AI 处理器市场的重要份额,但该公司具有成本效益且可扩展的 AI 解决方案,可以满足英伟达无法触及的多种应用需求。不止 Tenstorrent,多家新创 AI 芯片公司也将在未来几个季度推出类似应用的·AI 芯片产品。总之,不与英伟达正面竞争,越来越多的 AI 市场新进入者更看重那些没有被「绿色团队」占据的市场。
AI 芯片的创新一直在进行着,除了算力的提升,AI 芯片在架构、功耗、整合度等方面还有很大的优化空间。例如,通过先进的封装技术,多个 AI 芯片可紧密整合,可大幅提升系统带宽和能效。AI 专用的内存技术,如 HBM、压缩内存等,也将得到更广泛的应用。
挑战英伟达生态系统
除了芯片技术创新,AI 的生态系统建设也很重要。英伟达的 CUDA 平台经过多年发展,已经形成了庞大的开发者社区和丰富的软件资源,这是其竞争力的重要保证。
其他厂商也纷纷跟进,围绕自己的 AI 芯片建构生态系统,争取开发者的支持。Google 推出了基于 TPU 的 TensorFlow 深度学习框架,并开源了相关代码;AMD 收购了 Xilinx;英特尔推出了 OneAPI 开发工具套件,试图统一 CPU、GPU 和 AI 加速器的程序开发接口。
Arm、英特尔、高通、三星等合作组建了统一加速基金会 (UXL),目标之一就是取代英伟达的方案。
在 AI 系统当中,芯片互联技术很关键,特别是数据传输带宽,对系统性能的发挥起着重要作用。英伟达在这方面一直在建设自家生态,该公司最新的 Blackwell GPU 在多芯片互连、网络互连方面,将使用新推出的 NVLink 标准协议,在数据中心网络中,英伟达使用的是自家的 InfiniBand 总线。
对于英伟达这种封闭的生态系统,Jim Keller 很看不惯,他是开放技术的忠实拥趸,对于那些封闭技术深恶痛绝。
Jim Keller 提出,英伟达不应该使用私有的 NVLink 标准协议,应该换成开放的以太网标准,他还认为,在数据中心网络中,英伟达不该使用 InfiniBand,也应换成以太网,因为 Infiniband 虽然具备低延迟、高带宽(最高可达 200Gb/s)特性,但以太网能做到 400Gb/s,甚至 800Gb/s。
实际上,AMD、博通、英特尔、Meta、微软、甲骨文等巨头正在合作开发下一代超高速以太网 (Utlra Ethernet),其吞吐量更高,更适合 AI、HPC 应用。
那么,新的以太网技术能否发展起来,并抗衡英伟达的互联技术呢?
2023 年 7 月,多家行业巨头成立了超级以太网联盟(Ultra Accelerator Link,UALink),旨在与英伟达的 InfiniBand 抗衡。
AMD 正在为 UALink 努力贡献更广泛的 Infinity Fabric 共享内存协议和 GPU 专用 xGMI,所有其他参与者都同意使用 Infinity Fabric 作为加速器互连的标准协议。英特尔高级副总裁兼网络和边缘事业部总经理 Sachin Katti 表示,由 AMD、Broadcom、Cisco Systems、Google、Hewlett Packard Enterprise、英特尔、Meta Platforms 和 Microsoft 组成的 Ultra Accelerator Link「推广小组」正在考虑使用以太网的第一层传输协议和 Infinity Fabric 作为将 GPU 内存链接到类似于 CPU 上的 NUMA 的巨大共享空间的一种方式。
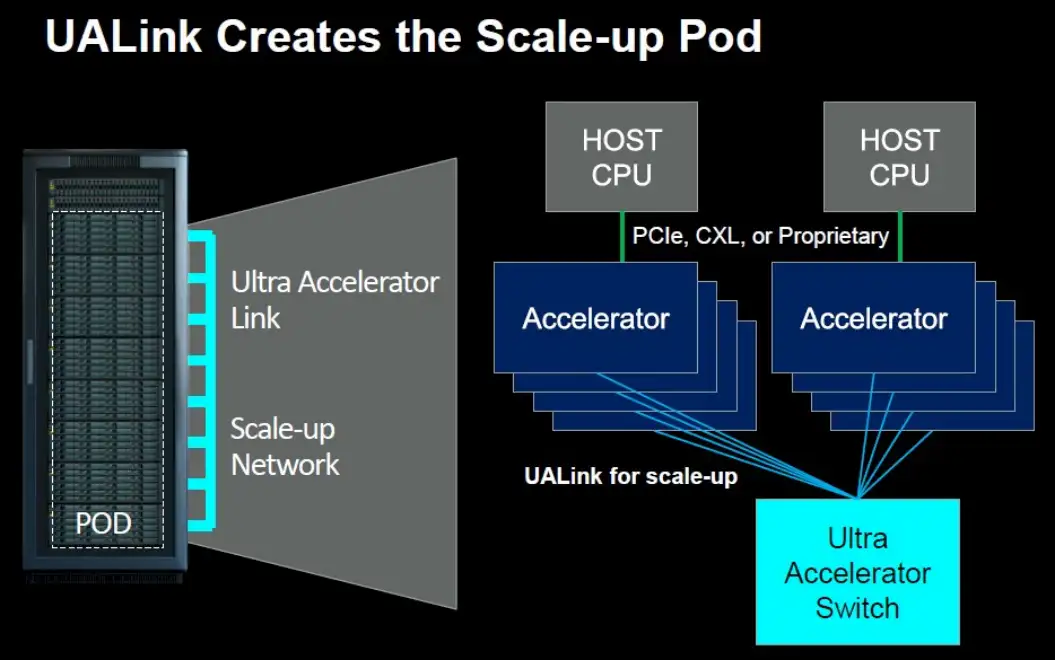
UALink 联盟成员相信,系统制造商将创建使用 UALink 的设备,并允许在客户构建他们的 Pod 时将来自许多参与者的加速器放入这些设备中。您可以有一个装有 AMD GPU 的 pod,一个装有英特尔 GPU 的 pod,另一个装有一些来自其他厂商的自定义加速器的 pod。该设备可以实现服务器设计的通用性,就像 Meta Platforms 和 Microsoft 发布的开放加速器模块(OAM)规范一样,系统板上的加速器插槽具备通用性。
据 IDC 统计,在超大规模企业、云构建者、HPC 中心和大型企业中,200Gb/s 和 400Gb/s 网络的建设已经足够多,InfiniBand 和以太网市场可以同时增长。
以太网无处不在——边缘侧和数据中心——这与 InfiniBand 不同,后者专门用于数据中心。IDC 表示,2023 年第三季度,数据中心以太网交换机的销售额同比增长了 7.2%。
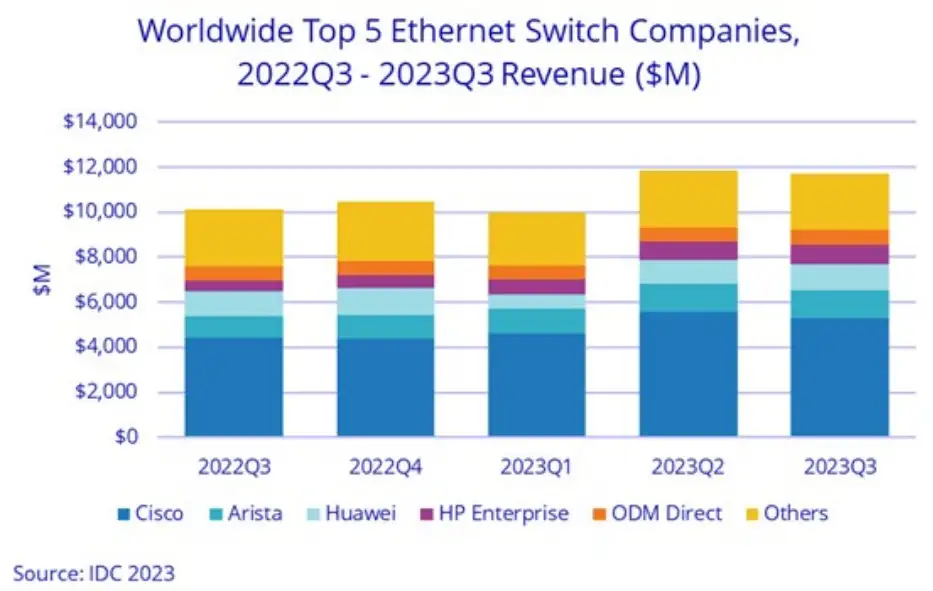
在 2022 年第三季度到 2023 年第三季度期间,数据中心以太网交换机的市场规模约为 200 亿美元,如果交换占 InfiniBand 收入的一半,那么数据中心以太网交换规模仍比 InfiniBand 交换大 7 倍左右,并且,有越来越多的 AI 集群迁移到以太网,它们正在蚕食 InfiniBand 的市占率。
IDC 表示,在以太网交换机市场的非数据中心部分,销售额增长更快,2023 年第三季度增长了 22.2%,前三个季度总共增长了 36.5%,因为很多公司升级了园区网络。
2023 年第三季度,数据中心、园区和边缘侧的以太网交换机市场规模达到 117 亿美元,同比增长了 15.8%。配套以太网路由器市场下降了 9.4%,这并不奇怪,因为路由器越来越多地使用包括交换和路由功能的商用芯片构建。
在数据中心,200Gb/s 和 400Gb/s 以太网交换机的销售额同比增长了 44%,端口出货量同比增长了 63.9%。数据中心、边缘侧和园区的 100Gb/s 以太网交换机的销售额增长了 6%。
结语
英伟达在云计算和数据中心 AI 系统方面的优势非常明显,无论是芯片行业巨头,还是新创公司,要想在这一赛道与英伟达 PK,难度很大,特别是新创公司,前些年以英伟达 GPU 为竞品,走同一赛道的几家小公司,日子过得都不太好,有的甚至在破产边缘。只有 AMD、英特尔这样的大厂可以在同一赛道与英伟达玩一玩。
云计算和数据中心 AI 赛道不好追,那就主攻低功耗、低成本的边缘侧应用市场,这也是一个很大的市场,且发展空间广阔,而目前市场上对口、适用的芯片又不多。在这种情况下,谁动手早,尽快拿出实用的产品,谁就能在未来竞争中占得先机。
除了 AI 芯片,互联技术和标准也是一个很有潜力的投资方向,而且在数据中心和边缘侧都有机会。英伟达的互联和总线技术不可能面面俱到,随着 AI 技术不断渗透到各行各业,以及各个性能、功耗和成本应用层级,芯片和系统互联的发展空间会越来越大,大大小小的公司都在摩拳擦掌。

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码