电子产品世界
业界动态
EEPW观点
网络与存储
论坛
博客
betway体育官网
betway必威娱乐城
网络与存储
CODACA科达嘉电子连续推出两款车规级功率电感 满足AEC-Q200
2022-07-08
2022-07-08
RS485转LoRaWAN “无缝”切换,星纵智能数传终端DTU上新!
2022-07-08
2022-07-08
累计出货190亿颗!兆易创新NOR闪存高居全球第三
网络与存储
2022-07-08
2022年Nor Flash产值将增长21%至35亿美元
网络与存储
2022-07-08
铠侠为实现超高容量SSD,正试验7bit/cell超高密度的3D NAND Flash
网络与存储
2022-07-08
网络与存储
2022-07-08
兆易创新vs北京君正,汽车存储芯片估值浅析
网络与存储
2022-07-08
盈利能力大增,估值较低的存储龙头被看好?
网络与存储
2022-07-08
友普加入红帽CCSP,加速中国市场混合云创新
2022-07-08
梦之墨应邀支持江苏省教育厅高等职业院校教师培训项目
2022-07-08
贸泽荣获Vishay颁发的三项年度分销商大奖
2022-07-08
论如何降低48V轻混汽车系统中的噪声辐射
2022-07-08
汽车ADAS进化的百年历史(三)
2022-07-08
点击查看更多
电子设计方案
东为 DW232Y指纹识别串口电路模块设计
2022-07-08
控制电路
外接通信
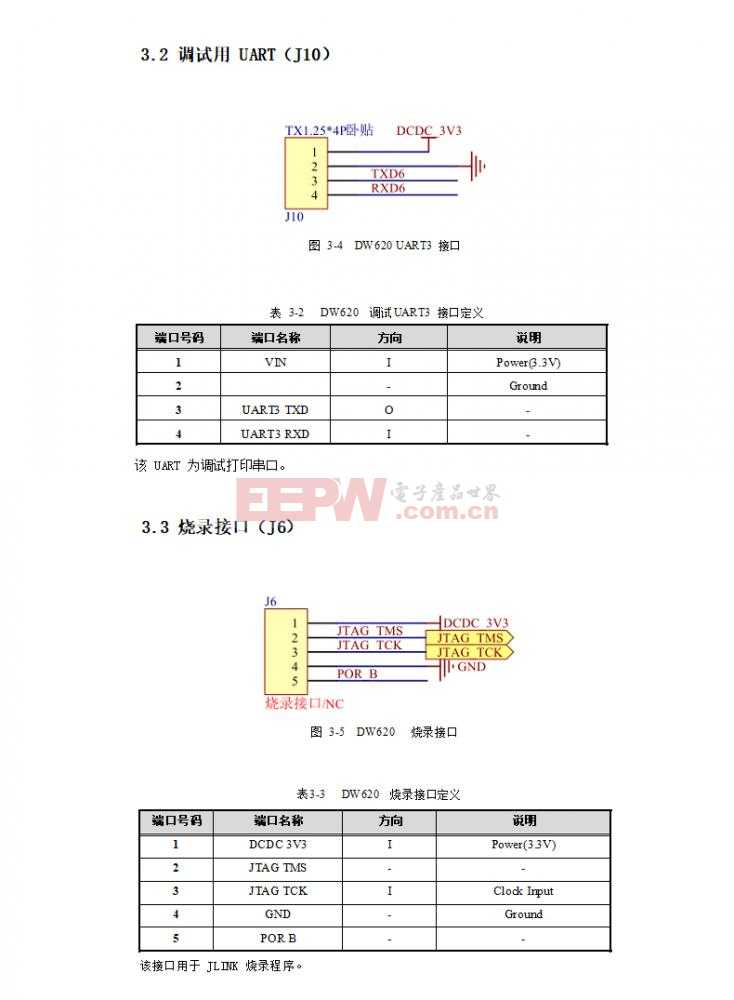
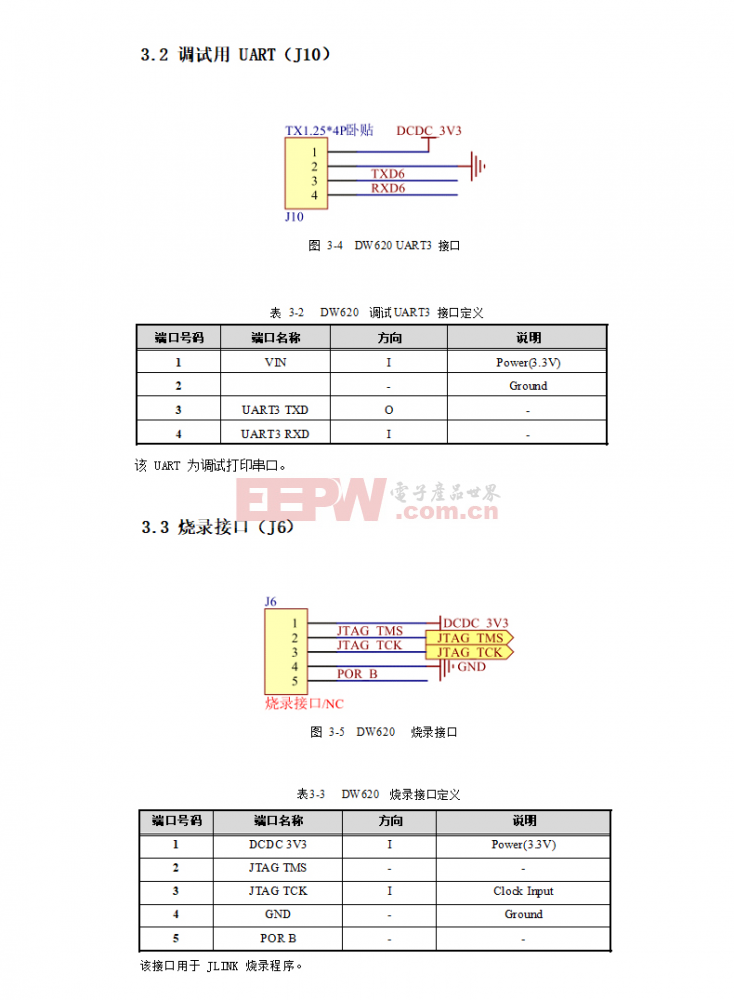
东为 DW620人脸识别模块接口电路设计
2022-07-08
接口电路
控制电路
优库 DW232Y指纹模块接口电路图
2022-07-08
接口电路
控制电路
优库 DW620人脸识别模块接口电路图
2022-07-08
接口电路
控制电路
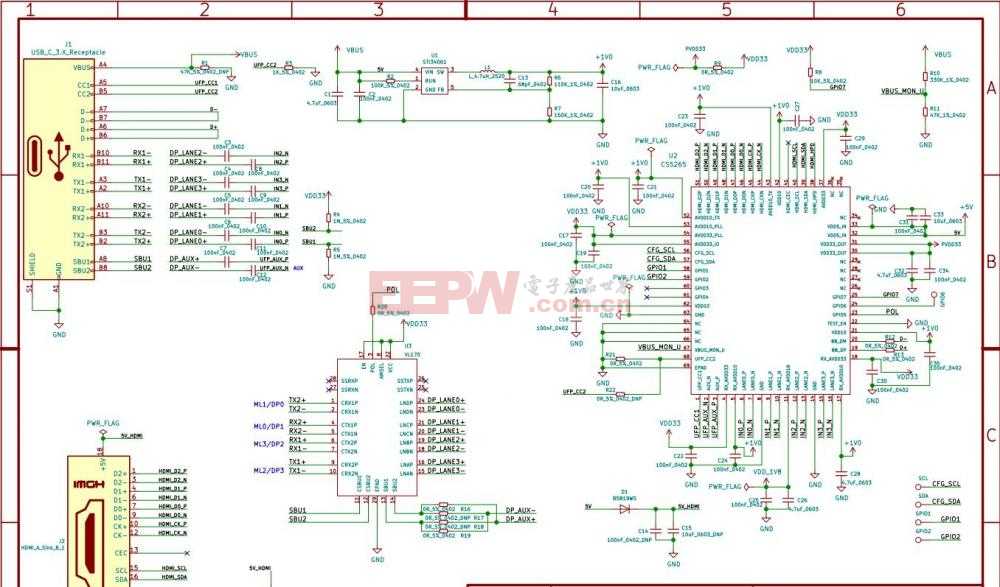
TypeC母座正反插转HDMI扩展投屏方案芯片CS5265+VL170设计参考电路
2022-05-13
CS5265母座正反插
typec扩展
投屏方案
白皮书
通过自动插入过孔减少 IR 和 EM 问题
上传时间:2021-11-01
文件类型: PDF
文件大小: 578.62K
使用电阻和电流密度数据调试 P2P 结果
上传时间:2021-11-01
文件类型: PDF
文件大小: 890.95K
IC中的高级电气规则检查
上传时间:2021-11-01
文件类型: PDF
文件大小: 670.27K
半导体设备控制附加软件介绍文档下载(内含影片)
上传时间:2021-09-09
文件类型: PDF
文件大小: 754.93K
Quick and Easy Tips for Solving EMI Issues(解决 EMI 问题的快速简便技巧)
上传时间:2021-08-25
文件类型: PDF
文件大小: 954.83K
可配置且简单易用的组合式可靠性检查
上传时间:2021-03-31
文件类型: PDF
文件大小: 1280.95K
MENTOR、AMD 和 MICROSOFT 合作开展云上 EDA
上传时间:2021-03-31
文件类型: PDF
文件大小: 571.97K
颠覆性的半导体测试方法
上传时间:2021-02-03
文件类型: PDF
文件大小: 10589.92K
CMP 建模的机器学习方法
上传时间:2021-01-20
文件类型: PDF
文件大小: 1902.86K
树莓派杂志《The MagPi》第101期(英语原版)
上传时间:2021-01-11
文件类型: PDF
文件大小: 32791.44K