独家专访AMD高级副总裁王启尚:打造开放生态链 拥抱AI大时代
王启尚先生有着30多年的显卡和芯片工程研发经验,目前在AMD负责架构、IP和软件等GPU技术开发,同时领导着AMD显卡、数据中心GPU、客户端和半定制业务SoC的工程研发。
访谈从AI LLM大语言模型开始。
王启尚在此前3月份北京举办的AMD AI PC创新峰会上就开门见山地分析了LLM的发展趋势,大型闭源模型越来越庞大,比如GPT-4的参数量已经达到1.76万亿;即便是相对小型的开源模型也在膨胀,Llama 2参数量达700亿,阿里通义千问2达到720亿。
如此庞大的LLM,对于算力的需求是十分“饥渴”的,同样需要海量的电力去支撑,远超一般数据中心的承受能力,越发引起行业的担忧。
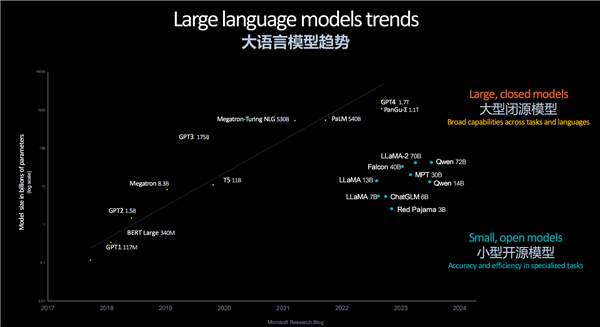
对此,王启尚分析指出,基础大模型的参数规模成长曲线比摩尔定律来得还要猛烈,几乎每两年就增长多达5-10倍,所以诞生了新的“混合专家模型”(MOE)策略,将单一大模型变为众多专家模型的集合,每一个都有自己专门擅长的领域,因此不需要超级庞大甚至无限制,相信未来会越来越流行。
在硬件方面,每一年都在更新换代,匹配大模型的快速进化趋势,重点就是提升算力和算法、内存容量和带宽。
其中,算力和精度密切相关,趋势是越来越低,前几年需要16位,现在逐渐转向8位精度,AMD下一代CDNA4 MI350会进一步降至6位或者4位,而最终可能会走向2位或者1位——人脑就是1位或者2位的。
当然,这个精度也要看模型的设计,有时可能需要量化和重新训练。
目前来看,没什么“魔法”大幅降低硬件的功耗,能做的就是努力提升能效。
比如AMD的下一代产品,性能可以提升35倍,但功耗不会增加这么多,客户依然愿意购买越来越多的GPU,毕竟算力依然不够。
王启尚承认,电力的问题会一直存在,未来数据中心可能真的需要自建发电厂。

回到距离我们更近的AI产品,比如说Strix Point的下一代移动处理器锐龙AI 300系列,NPU的算力达到了50TOPS,可以满足更多对算力有需求的场景,更多地接手CPU、GPU的工作。
王启尚表示,每一种AI引擎都有适合自己的工作,比如CPU主要做通用运算,GPU可以快速训练大模型,NPU则可以达成最低的功耗和最高的能效,当然将负载迁移到NPU上都需要一定的优化和时间。
特别是在GPU、NPU之间,存在着折衷和妥协,取决于你看中高速度还是高能效。
另一方面,在未来,AMD希望通过多层的Graph Compile 编译器,根据系统里的AI引擎类别,可以将不同的负载分配给不同的AI引擎,让CPU、GPU、NPU同时跑起来,达到最高效率。
不过这方面还需要一定的时间,目前仍是将全部的工作负载放在同一个编译器里执行,我们能做的是让整个模型变得更成熟,使其简单地进行编译最佳化,但这仍需要一定的人力成本。

当笔者问到,说起CPU、GPU、NPU的多引擎组合,Intel也已经具备全线实力,NVIDIA也在尝试做自己的CPU,AMD又该怎么办呢?
王启尚认为,每一家厂商都有自己的独特优势,AMD的三种引擎在业内都是非常好的,也非常均衡。
未来,AMD将继续发挥三种引擎都可以提供最佳状态的优势,每一样都要做好,同时延续AMD一贯的企业文化,在软件方面坚持开源,和行业伙伴共同创新,打造开放的生态链,拥抱AI大时代。
比如AMD联合博通、思科、谷歌、慧与、Intel、Meta、微软共同宣布了开放的行业标准UALink(Ultra Accelerator Link),共同推进AI基础设施建设。
在这八大创始成员中,谷歌、慧与、Meta、微软都是数据中心客户,都非常高兴能有这样的开放标准,可以更标准化、更容易地扩建大规模数据中心,不会被限制在专有方案中。

最后聊到了王启尚的专长,也就是GPU发展,包括锐龙AI 300系列核显使用的RDNA 3.5(或者叫RDNA 3+),以及下一代显卡将会使用的RDNA 4。
具体细节目前肯定无法公开,不过王启尚透露,RDNA 3.5重点针对APU环境做了优化,比如集成图形核心规模从12个CU单元增加到最多提供16个CU单元(笔者换算为增幅33%),对于APU来说是非常强悍的,可以更好地用于游戏。
RDNA 4在游戏方面的重点就是通过AI增强游戏体验,包括更强的光线追踪,更多的AI加速画质和帧率。
事实上,这也是RDNA GPU家族发展的大方向。

根据王启尚先生的精彩分享,我们拭目以待AMD在未来的AI进击!

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码
相关文章
-
2024-08-06
-
-
2024-07-23
-
-
-
-
-