10nm SRAM、10核心芯片亮相ISSCC
一年一度的“国际固态电路会议”(ISSCC)将在明年2月举行,几乎所有重要的晶片研发成果都将首度在此公开发布,让业界得以一窥即将面世的最新技术及其发展趋势。三星(Samsung)将在ISSCC 2016发表最新的10nm制程技术、联发科(MediaTek)将展示采用三丛集(Tri-Cluster)架构搭载十核心的创新行动SoC。此外,指纹辨识、视觉处理器与3D晶片堆叠以及更高密度记忆体等技术也将在此展示最新开发成果。

三星将提供更多DRAM与快闪记忆体晶片细节,其中最重要的是一款采用10nm FinFET技术制程的128Mbit嵌入式SRAM。根据ISSCC主办单位表示,该元件具有“迄今最小的SRAM位元单元,”高密度(HD)型晶片尺寸约0.040μm,而高电流(HD)晶片版本的尺寸约0.049μm。该设计支援“整合型辅助电路,可分别改善HD与HC位元单元的最小操作电压(Vmin)至130mV与80mV。
The Linley Group微处理器分析师David Kanter表示,“相较于三星0.064μm2的14nm SRAM,10nm晶片版缩小了0.63倍,当然不尽理想;但相较于0.049μm2的英特尔(Intel)14nm SRAM,三星的记忆体单元则缩小了0.82倍,这是三星未在20nm与14nm之间微缩金属规律的结果。”但Kanter预计英特尔的10nm SRAM尺寸应该会更小。
台积电(TSMC)在今年初就宣布了10nm制程。据报导台积电正为苹果()下一代iPhone所用的处理器SoC加码制程投入。三星与台积电目前都是 iPhone SoC的主要供应来源。
全球最大的晶片制造商——英特尔已经延迟推出10nm晶片的计划了,原因在于不断攀升的成本与复杂度导致实现这一目标所需的下一代微影技术持续延迟。尽管可能由于10nm晶片的某些关键层必须使用三重图案而压缩了利润,但三星与台积电并没有什么选择,如果他们想赢得的订单的话——这可能是业界最大的一笔交易。
除了三星的SRAM,台积电还将在ISSCC中透露16nm FinFET制程的更多细节。英特尔则可能揭示在开发下一代晶片过程中日益增加的复杂度与成本等挑战。英特尔制造部门总经理William M. Holt表示:“由于我们不断面对微缩带来的挑战,人们越来越担心与质疑摩尔定律(Moore"s Law)在迈向未来时的生命力。”
为了推动摩尔定律持续进展,创新的3D异质整合机制以及新的记忆体技术将有足够的潜力最佳化记忆体层,从而克服处理器性能、功率与频宽等挑战。” 3D堆叠超越摩尔定律挑战
随着晶片制造的成本与复杂度不断攀升,业界厂商正积极探索3D堆叠技术,期望以其作为提高性能或降低功率的替代方法。
三星将揭露多达8个DRAM晶片的堆叠,可达到307Gbits/s的频宽,较ISSCC 2014发表的128Gbits/s堆叠倍增了频宽。三星并为该20nm晶片加入锁相环,从而简化晶片测试。为了降低热,该公司还采用“一种可衡晶片温度分布的自适应刷新方案。”
海力士(SK Hynix)将展示256Gbit/s频宽的DRAM堆叠,“可在堆叠的逻辑层……为记忆体核心处理指令解码与偏置产生”,而不像以往设计是在记忆体层进行。此外,它还在负载过重的3D互连上采用较小摆幅讯号传输,以便降低功耗驱动互连。这种高密度的记忆体晶片将有助于实现高性能运算、加速器以及小型绘图卡。
三星另一款256Gbit的快闪记忆体晶片支援每单元3位元储存,使用了48单元层的晶片堆叠。三星率先在快闪记忆体设计导入单晶片堆叠,展现无需更先进制程技术即可实现更密集晶片的发展路线。
美光科技(Micron)的目标在于超越三星的技术,最新的768Gbit的快闪记忆体晶片可在179.2mm2的面积上支援64KB页缓冲,并藉由在阵列下方放置周边电路实现最高密度NAND快闪记忆体。这种密集晶片将有助于推动固态硬碟(SSD)市场——据统计,这一市场预计将在2016年达到200亿美元的市场规模。
法国研究机构CEA-LETI则将揭露晶片堆叠技术,专为3D电路而打造的4×4×2异步网路晶片(NoC)采用了65nm制程。该晶片瞄准先进的蜂巢式网路设备,并以约0.32pJ/b的3D I/O供电电流实现最低的能耗,以及最高达326Mbits/s的高资料率。
指纹辨识、机器视觉技术大跃进
ISSCC2016还将亮相从指纹辨识到机器视觉与DNA测序等多项最新技术应用。
应美盛(Invensense)与加州大学(University of California)携手的团队开发出利用110×56 PMUT阵列键合CMOS晶片的超音波指纹感测器,能以2.64ms提供431×582 dpi的影像,而功耗仅280uJ。“这款超音波指纹感测器能够成像表面的表皮以及近表面的真皮指纹,使其不受汗渍、防电子欺骗,因而能够为行动装置带来高度可靠性且低成本的个人ID感测。”
韩国与美国的研究人员将发表先进的机器视觉技术进展。韩国科学技术院(KAIST)将介绍“透过整合65nm多核心深度学习处理器而实现的最高准确度智慧眼镜影音介面,”ISSCC表示,这款处理器可提供较上一代处理器(针对头戴式显示器应用)更高56.5%的功效,以及较现有最佳图形辨识处理器更高~2%的辨识率。
美国麻省理工学院(MIT)的研究人员将发表“高效率的深度学习处理器,能够灵活地映射先进的深层神经网路。”这款65nm晶片是一款“深度卷积神经网路(CNN)加速器,搭载了168个处理单元的空间阵列与可配置晶片上网路,可支援像AlexNet等先进CNN。相较于行动绘图处理器(GPU),它的功耗更低10倍,而且仅需更少4.7倍的每画素DRAM存取。
MIT的研究人员还将介绍一款3D视觉处理器,利用来自飞行时间(ToF)相机的资料为视障者打造导航装置,能以30fps的速率侦测安全区域与障碍物,而利用仅0.6V供电消耗8mW功率。这一类先进的视觉晶片将瞄准智慧眼镜与显示器应用,根据市调资料显示,这一市场预计将在2020年成长至1,200亿美元的市场规模。此外,还可应用于无人驾驶车与无人机。
英特尔与加州大学研究人员将共同发表一款经概念验证的DNA测序晶片。这款32nm的晶片在CMOS读取电路上整合了8,192画素的奈米裂隙(nanogap)转换器阵列,从而为DNA测序创造一种电化学生物感测技术,同时还能具有高讯号杂讯比(SNR)。“现有的DNA测序解决方案通常不是使用难以微缩的光学感应技术,就是SNR低的分子感测方式,如今这种新途径可望为整合于电子产品应用的更小尺寸、更低成本DNA测序铺路。”
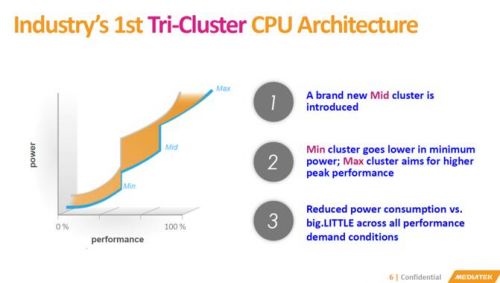
联发科展示的首款三丛集、十核心CPU,搭载三个ARMv8a CPU丛集,以20nm高κ金属闸制程为1.4GHz、2.0GHz与2.5GHz作业实现最佳化。相较于双丛集架构CPU,额外增加第三个丛集提高了40%的整体性能与功效。
“单纯地添加更多核心并不一定就能提高处理性能。”Kanter指出,“采用big.LITTLE的配置,就容易瞭解电管源理在什么时候时使用小核心以及何时用大核心。但问题是我不确定大小核心之间的间隔对于中间选项是否足以确认中间选项,以及电源管理如何利用这些核心。”

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码
相关文章
-
-
国际视野 2022-11-20

-
-
-
-
-

-
