软件化和网络化的基于Linux的雷达终端系统
分解过程相当于输入序列和滤波器卷积后,进行亚采样,只保留偶数点;合成过程相当于先对序列进行插值(添加0)后,再与滤波器卷积、相加。
图4是一个用db1小波递归3次压缩一段雷达回波的例子,压缩接近原来的1/8。
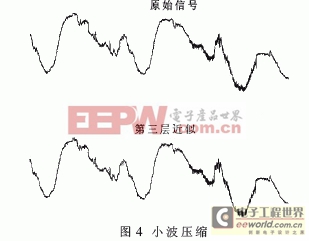
系统中采用 (9,7)双正交小波快速提升算法,根据实际需要进行1~4层尺度分解。小波压缩实现细节可参考文献[2]。
2.3 网络传输
常用的网络协议是UDP和TCP。UDP是面向无连接的协议;TCP是面向有连接的协议。另外,TCP协议在接收方还要进行包的次序调整,因为不同的包可能按不同的路由到达。然而,可靠是要付出代价的,TCP占用CPU资源要比UDP高,网络利用率也不如UDP。如果网络状况良好,需要持续进行大批量的数据传输,可以考虑UDP。一般情况下,通讯方式都是点对点的,也就是所谓的单播方式。采用这种方式,多个客户机必须与同一个服务器分别建立连接,这导致了网络负载成倍增加。
在特殊情形下可以使用广播方式。其目前只被UDP协议支持。广播的实现非常容易,只需要将目的IP地址设置为该段子网的地址即可。这种一对多的方式会影响不需要接收的主机,子网上所有未参加广播接收的主机也必须完成对数据报的协议处理,直至UDP层才将它丢弃,甚至还会引起广播风暴。
单播和广播是两种极端。多播提供了一种折衷的方案。多播数据报仅由对该数据报感兴趣的主机接收(该主机加入多播组),不会影响子网上其它主机。目前UDP提供对多播的支持。
系统中,一次视频采用多播方式;主显示机与预处理机之间的操控命令连接通道由于需要可靠的连接且通信量相对较少,所以采用了面向连接的TCP协议。
3 主显机系统的实现
主显机主要由各种显示模块和网络模块组成。显示模块包括PPI和AR模块。其中以PPI显示技术最为复杂,显示模块和网络模块如何整合是系统效率高低的关键。
3.1雷达视频PPI显示
3.1.1坐标变换和死地址
显示过程中一个很重要的步骤是进行坐标的转换。数据采集卡得到的雷达视频数据以距离方位为坐标,但通用显卡的内存则以行列为坐标,故极坐标要转化为x-y直角坐标,极坐标与自然直角坐标转换为:
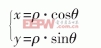
如果实时计算,目前的计算机硬件条件无法达到实时要求。可事先计算好,转换时采用查表法,以空间换取时间。转化表可以只计算第一象限,其它象限根据方位码对称性确定。
所谓死地址,是指PPI显示中远离显示中心的地方会有部分区域始终访问不到,从而产生类似于衍射花纹的现象。半径愈大时,这种花纹愈明显。如图5所示。
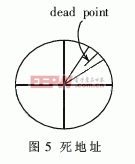
需要把这些不能被访问到的点“补”上。将原有的一些有重复(即多个(ρ-θ)点映射到同一个(x-y)坐标)的点分开,以最近为原则将其中的重复点强行改为“死地址”点。例如,极坐标下的两个点M1(ρ1,θ1)和M2(ρ2,θ2),转换为直角坐标后对应的点都是M3(x1,y1),而点M4(x2,y2)是“死地址”且M3和M4相隔很近,这时强行规定M1=>M3而M2=>M4。
系统中,不偏心时,扫描半径是512像素,一周4096根扫描线。实践证明可以将所有的死地址与相邻的方位距离码关联起来,消除花纹图案。可以想象:扫描半径越大,远离圆心的死区面积越大,其附近通常找不到能够利用的重复点,必须改进方案。
考虑最极端的情形,偏心在圆周上,此时最大扫描半径为1024。将半径1024的圆分为半径512的同心圆和剩下的外圆环。内部的小圆可以用前面的方案。512~1023部分将方位分辨率提高一倍,即一周8192根,再进行补点。具体算法如下:
(1) 得到外圆环的所有x-y坐标点的集合。
(2) 将外圆环内所有的ρ-θ点按转换公式四舍五入到最近的x-y坐标点。有些x-y会关联多个ρ-θ点,有些则没有ρ-θ点与之关联。
(3) 遍历那些没有ρ-θ关联的x-y。对于每个这样的x-y点,查找以自己为中心、边长为4的正方形内所有的x-y点,如果发现某一个x-y点关联ρ-θ多于一个,就将其中的一个ρ-θ给这个没有ρ-θ关联的x-y。同时,给出ρ-θ的x-y点,在其ρ-θ关联链表中去掉给出的ρ-θ。
(4) 按ρ从512~1023、θ从0~8191的顺序将对应的x-y写入磁盘文件中。
编程计算结果表明这种算法可以很快地补全所有死地址。
相应地,原来的坐标转换表应该由补过死地址的两张表(一张是半径512以内,另一张是512~1023)代替。

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码