Web文档聚类中k-means算法的改进
利用向量空间模型对文档进行聚类只能根据文档的二种信息:(1)文档中每个特征词出现的频率;(2)文档的长度。由于文档长度与文档所属的类别之间的关系不大,因此可以把所有的文档长度进行归一化处理,从而使文档向量具有统一的特征维数m。

其中:m为特征向量维数,αk为二个文档对应特征词条的四位码字的十进制数值差的绝对值。由于这种相似性的计算使用的是整数,所以计算速度和精度得到一定的提高。
可以利用简单的示例验证公式(5)的合理性。当二个文档完全相似时,sim(di,dj)的值等于1,而二个文档完全不同时它的值为0。这种方法不仅反应了文档之间的差异,而且定量地描述了这种差异性,从而为文档的聚类提供了依据。下面通过对具体的Web文档进行实验并进一步地验证。
3实 验
实验用的文档是从搜狐的中文网站上获取的娱乐类文档,选用其中的1500篇。对这1500篇文档进行手工分类,如表1所示共分为10类。

衡量信息检索性能的召回率和精度也是衡量分类算法效果的常用指标。然而聚类过程中并不存在自动分类类别与手工分类类别确定的一一对应关系,因此无法像分类一样直接以精度和召回率作为评价标准。为此本文选择了平均准确率作为评价的标准。平均准确率通过考察任意二篇文章之间类属关系是否一致来评价聚类的效果。
试验中对使用公式(3)和(5)的改进k-means算法和原k-means算法的平均准确度进行了比较,实验结果如表2所示。
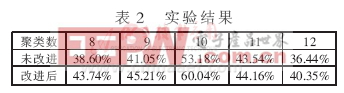
实验结果表明,改进后的k-means算法与原k-means算法在运行速度上基本相同甚至略快,平均准确度则比原算法有了普遍提高,尤其在正确指定聚类数k时,平均准确度提高了近7%,说明此算法具有较高的准确性。由于实验中使用的文档集很小,所以改进的算法优势不很明显。
4结束语
本文对k-means算法进行了改进。根据不同位置的特征词条对文档内容的不同决定程度,提出一种新的文档特征词条的权重评价函数,并在此基础上提出一种文档相似性的度量方法。实验表明改进后的算法不仅保留了原k-means算法效率高的优点,而且在平均准确度方面比原算法有了较大提高。实验还表明,k-means算法要依赖原始聚类数k的选择。如何为初始文档集选择合适的聚类数k以及进一步提高平均准确度是今后改进k-means算法的主要研究方向。

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码