Web文档聚类中k-means算法的改进
2 k-means算法的分析及其改进
2.1 权重评价函数的改进
k-means算法采用向量空间模型(VSM)将Web文档分解为由词条特征构成的向量,利用特征词条及其权重表示文档信息。向量d=(ω1,ω2,ω3,∧,ωm)表示文档d的特征词条及相应权重。其中:m为文档集中词条的数目,ωi(i=1,∧,m)表示词条ti在文档d中的权重。特征权重ωi的计算通常采用经典的TF*IDF算法,并进行规格化处理:
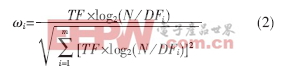
其中:TF表示该词条ti在文档d中的频数,DFi表示文档集中包含词条ti的文档数,N表示文档集中的文档数。从公式(2)可以看出,这种特征权重的计算方法是把文档当做一组无序词条,词条特征权重只是体现了该词条是否出现以及出现次数多少的信息,而对于词条在文档中的不同位置对文档内容的决定程度不同这一问题却未加考虑。
对于Web文档而言,由于XML(可扩展标识语言)已经成为Web上新一代数据内容描述标准,因此Web上的文档聚类应体现XML文档的特性。XML文档中的基本单位是元素(element)。元素由起始标签、元素的文本内容和结束标签组成。它的语法格式为:
标签> 文本内容
基于XML的Web文档中,用户把要描述的数据对象放在起始标签和结束标签之间,无论文本的内容多长或者多么复杂,XML都可以通过元素的嵌套进行处理。不同标签下,同一个词条也可能有不同含义。由此可见,XML文档中不同位置的词条对文档内容的决定程度会有很大的不同。
通常,一个文档的标题、摘要、关键词以及段首和段尾出现的词条对整个文档内容有很大的决定作用。在XML文档中,通过标签可以得出词条对文档内容的决定程度,但很难对这种决定程度进行准确的定义。因此,本文利用模糊集理论,根据XML文档特性计算词条从属关系系数,并且将其量化为介于0和1之间的隶属度,加入到原有权重评价函数,从而表明XML文档具有该词条特征的程度。
为了简化计算,词条在文档中出现的位置主要分为标题、摘要、关键词、段首尾、特殊标识处和正文几个部分。其相应权重为σt,在[0,1]之间取值,用lt表示词条在相应位置出现的次数。加入了词条隶属度的权重评价函数为:

2.2 相似性度量的改进
利用向量空间模型处理Web文档时,由于文档的繁杂性,表示文档的特征向量可以达到数万维,甚至更多。通过预处理阶段停用词和无用高频词的过滤后,特征向量的维数虽然显著减少,但剩余的维数仍然很多。本文实验中选用的娱乐类1500篇Web文档在预处理后特征向量的维数仍然达到了8291维。
如此高维的特征向量使得聚类算法的处理时间大大增加,同时对算法的准确性产生不利影响,并且这些特征对于聚类来说大多是无用的,例如聚类算法STC(Suffix Tree Clustering)将特征向量的维数减少到几十维仍然能够准确聚类。这主要是因为,对于非结构化的文档,体现其类别特点的特征词有很多,当进行某一方面的聚类时,与此无关的特征词就成了噪音。从这一点来说,文中前面改进的权重评价函数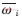 体现了特征词对文档内容的贡献程度,从而突出了与聚类相关的特征词,降低了无关特征词的干扰。另一方面,过多的特征词使得特定的特征词出现的频率较低,容易被噪音所淹没。
体现了特征词对文档内容的贡献程度,从而突出了与聚类相关的特征词,降低了无关特征词的干扰。另一方面,过多的特征词使得特定的特征词出现的频率较低,容易被噪音所淹没。
k-means算法使用基于距离的相似性度量,通过计算文档向量之间的距离表明文档之间相似性的大小。通常采用的是余弦函数,计算公式为:


加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码