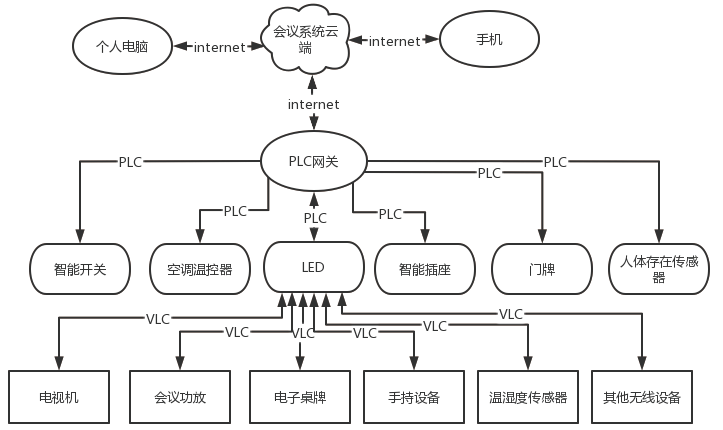
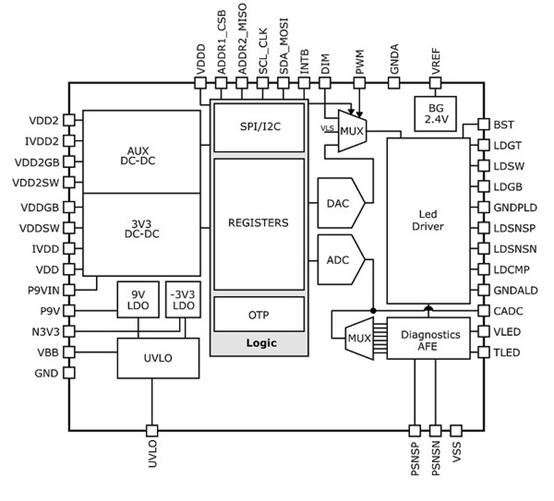
基于FPGA的并行可变长解码器的实现技术
可变长编码(VLC)是一种无损熵编码,它广泛应用于多媒体信息处理等诸多领域。在H.261/263、MPEG1/2/3等国际标准中,VLC占有重要地位。VLC的基本思想是对一组出现概率各不相同的信源符号,采用不同长度的码字表示,对出现概率高的信源符号采用短码字,对出现概率低的信源符号采用长码字。Huffman编码是一种典型的VLC,其编码码字的平均码长非常接近于数据压缩的理论极限——熵。
可变长解码(VLD)是VLC的逆过程,它从一组连续的码流中提取出可变长码字,并将之转换为对应的信源符号。由于在VLC过程中,码字之间通常不会加入任何分隔标识,这就造成了在解码过程中识别码字的困难。因此,在VLD过程中,变长码字必须逐一识别,只有码流中居前的码字被识别之后,才能定位后序码字的起始位置,这一点在很大程度上限制了VLD运行的效率。
本文讨论一种新型的VLD解码结构,它通过并行侦测多路码字,将Buffer中的多个可变长码一次读出,这将极大地提高VLD的吞吐量和执行效率。然后采用FPGA对这种并行VLD算法的结构进行验证,最终得出相应结论。
1 算法描述
由于码流中的可变长码之间具有前向依赖性,因此如何确定可变长码码字在连续码流中的起始位置是VLD的关键所在。传统的VLD解码方案主要为位串行解码方案和位并行解码方案两种。
在位串行解码方案中,码流逐位送入解码器,解码器通过逐位匹配实现可变长码的解码。这种过程实质上是一种建造Huffman树的反过程,从根节点出发,直至叶子节点为止。由于这种方式采用逐位操作方式,而可变长码的码长又各不相同,使得码字识别所需的运行周期也不相同。在解码长较短的码字时,其解码速度较快,而在解码长较长的码字时,其解码速度较慢。显然,位串行解码方案效率相对较低,解码速度因码字长度不同而不同,无法满足某些对实时性要求较高的应用场合。
针对位串行解码方案的不足,多种位并行解码方案被提出。位并行解码方案采用并行方式工作,通过对可变长码的码字进行排序(Ordering)、分割(Partitioning)和簇化(Clustering),采用基于逻辑块的匹配模式中其它树的匹配模式来实现。并行解码方案大大提高了可变长码的解码效率,而且可以确何每个运行周期输出一个解码码字,实现稳定的解码输出。在高级的位并行解码方案中,还可以将解码过程分解为若干阶段,引入流水线操作,进一步提高解码效率。
在传统的VLD解码方案的基础之上,采用并行操作方式,增加硬件资源和相应的控制逻辑,可实现一个运行周期输出多个解码码字,使可变长码的解码效率进一步得到提高。
由于可变长码长度不同,在解码过程中码字存在前向依赖性。如果采用多路并行操作方式,在所有可能成为可变长码码字的起始位置同时进行预测,然后通过后续控制筛选出合法的码字,就可以对多个可变长码实现同时解码。这就是多符号可变长并行解码方案的基本思想。
具体说明如下:假设某个信源符号集有K个符号,K个符号所对应的变长码字用Ck=(cok,…,cimk-1)|ckl∈{0,1},k=0,…,k-1表示,这些变长码的长度为集合L,其中最长的码长用ln表示,最短的码长用l1表示;具有相同码长的码字最多为dmax个。现采用分页方式重新组织这些可变长码,将具有相同码长的码字存入一个页内,那么易知一个页内最多可能拥有dmax个码字。为了识别一个页内的不同码字,还需要引入页内偏移量,然后采用线性结构将这些页面重新组合。
下面给出一个依据该思想重新组织信源符号的实例:
对于存储在Buffer中的等待解码的数据码流X,用滑动窗口从中截取前N位,这里的N应当大于或等于可变长码中最长码字的码长,即N≥ln。由于可变长码最短的码长为l1,因此在这N位码流中,最多可包含M=[N/l1]个可变长码。为了表示方便,这里用Wi(i=0,1,…,M-1)表示这M个可变长码。
虽然,对于W0,其起始位置必然为0;如果W0的码长为L0,那么W1的起始位置则为L0;如果W1的码长为L1,那么W2的起始位置为L0+L1,依此类推。由于在解码开始时,L0的取值无法明确,其可能取值范围是l1≤L0≤Ln,因此每个Wi的可能起始位置分别由一组值组成。
为了实现并行解码,采用多个可变长码检测单元从所有可能的起始位置同时侦测,一旦W0的码长L0被侦测出,就可以从所有已解码的可能的变长码中找出W1,并确定W1的码长L1,由此W2的起始位置也就得以确定。依此类推,最多可逐次将Wi(i=0,1,…,M-1)个变长码解出。
每个Wi的解码过程只比Wi-1的解码过程多一个加法操作的延迟,相对于变长码的识别,加法操作的延迟非常的小。当然,如果滑动窗口N的取值过大,每个Wi之间的加法操作的延迟将累加,这将降低解码的整体效率。因此对于滑动窗口N的选择,需要结合实际应用中可变长码编码的特点来权衡。
设某个待解码流为B={110110100011000011001111,…}。这里采用长度N=12的滑动窗口进行码流提取,由于变长码的长度从2~8不等,因此每个运动周期至少可以解码出1个码字,最多可解码出6个码字,这6个变长码字可能的起始位置分别为W0:{0};W1:{2,3,4,5,6,7,8};W2:{4,5,6,7,8,9,10};W3:{6,7,8,9,10};W4:{8,9,10};W5:{10}。
综合起来,可能成为该可变长码起始位置的集合为{0,2,3,4,5,6,7,8,9,10},因此在应用上共需要10个可变长码检测单元并行执行。
2 实现与验证
多码字并行解码方法实现的关键在于解码过程的并行性,采用硬件方案实现起来并不 难。上例中10个可变长码检测单元可采用经典的位并行解码方案实现,因为位并行解码方案能够保证不同长度码字的输出时间基本相同,为其后的操作带来便利。在本文中,采用基于查找表的方式来实现。
码字检测单元所检测到的可变长码的码长及页内偏移量(这里采用码字的最右位作为页内偏移量),在识别过程中可能存在没有任何有效码字的情况。为此,增加了一位有效状态位,作为输出是否有效的标志。变长码检测单元CD的结构框图如图1所示。
由于前一个有效码字Wi-1的码长控制着码字Wi的选取,而对应Wi-1的检测单元Cdi-1输出了Wi-1的码长,因此在实现上可以采用将Cdi-1的输出作为有效码字Wi选取的控制位,它通过控制一个多路选择器MUX,从所有对应可能是Wi起始位置的CD输出中选取有效的输出作为有效码字Wi。在有效字Wi被成功识别后,需要将其码长即Cdi的输出与Cdi-1的输出相加,作为有效码字选择的控制。这些功能通过一个复合的多路复用器-加法器MA实现,多路复用器-加法器MA的结构如图2所示。
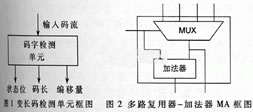
在所有有效码字的起始位置被识别后,根据对应CD单元的输出,即码长信息和页内偏移量,可以通过查表将对应的码长数据转换成相应的信源符号或存储相应信源符号的地址。这些功能由信号转换单元SYMBOL完成。
根据上面的讨论,设计出用于上例的多符号并行解码器,其结构图如图3所示。
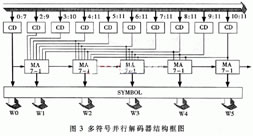
为了验证这种这种结构,采用FPGA器件实现它,选择的是一片Xilinx xc2s400e-6ft256器件,其规模为145000门。在这里,采用VHDL语言进行RTL级描述,利用XST进行综合,并在ModelSim5.8中进行仿真。结果验证正确,其仿真结果如图4所示。

实验表明,系统允许最大时钟频率为44.172MHz,占用了197个SlICe(4%),74个Slice Flip Flops(<1%),347个四输入查找表(12%)和1个全局时钟(25%)。
关键词: VLC

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码