基于KeyStone DSP的多核视频处理技术
随着越来越多的移动手持终端支持视频功能,对于流媒体内容及实时通信的网络支持需求也在显著上升。虽然对已部署的 3G 媒体网关进行升级可以支持较低的分辨率和帧速率,但这种由于自身的有限处理能力而进行的升级并不能满足视频成为主流应用的需求。
为了使可扩展视频应用能够支持高密度 (HD),需要显著提高视频处理能力,而多核数字信号处理器 (DSP) 不但拥有能满足此类需求的增强型视频处理功能,同时还能充分满足运营商在可扩展性和低功耗方面的需求。
本文旨在介绍一种全新的多内核平台,其能够通过优化内核通信、任务管理及存储器接入实现高密度视频处理能力,此外,本文还阐述了扩展实施的结果如何支持多通道和多内核 HD 视频应用的高密度视频处理。
1 介绍
3G 与 4G 移动网络在全球范围内的广泛部署以及无线创新热点的不断涌现,催生了手持终端用户所需的关键数据带宽。除了 web/数据应用以外,视频已成为移动数据普及的另一推动力。
随着越来越多的用户转而使用视频应用,网络基础局端需要实现显著的性能提升才能支持视频内容,这从最近苹果公司 Facetime 视频呼叫应用及类似应用的流行上可见一斑。
手持终端能够以更高的分辨率和帧速率支持视频捕获与播放。传统部署的 3G 媒体网关专用于支持低分辩率视频应用中的高密度多语音通道,但通常不能满足用户对于高质量的预期。
此外,由于手持终端因电池使用寿命和存储器大小等技术局限性,通常仅能以有限的参数集支持几种标准,因而媒体网关需要支持更多的编解码器和转码模式,如转码、传输量以及传输速率等。例如,当移动手机用户驾车高速驶过某个区域时,让网络去适应由当时瞬时链接条件提供的带宽并提供相应的压缩、分辨率及比特率更具高效性,这样视频链不致中断,而且手持终端也不会因支持缩放或剪辑造成带宽或电池电量的浪费。
为了充分满足这些需求,我们需要显著提高高密度媒体网关的视频处理能力。多内核 DSP 能够以较低运营成本提供可扩展的解决方案,从而全面解决运营商重点关注的功耗与空间占用问题。
本文的组织结构如下:
首先,阐述了处理高分辨率视频面临的挑战和资源需求,以及如何有效地实现带可扩展实施功能的视频编码算法,以便同时支持低分辨率和高分辨率通道。
其次,还对软硬件选项如何提高多内核运行的效率展开了讨论。
最后,本文回顾性介绍了多内核 DSP 领域前沿技术的发展历程,并探讨了开发人员可资利用的平台。
2 基础局端 HD 视频面临的挑战
图 1 描述了基于基础局端网络的视频通信系统。一个典型的系统应支持多种功能,其中包括:
- 高密度媒体的码制转换与速率适应
- 与视频转码相关的音频转码
- 大型多方视频会议
- 诸如语音等其他媒体形式的处理
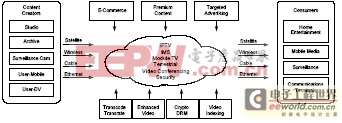
图 1 基于网路的视频通信
转码是一种典型的通信基础局端视频应用,我们可在其中通过已压缩的输入流对 YUV 域视频流进行解码,然后再使用不同的标准(转码)、不同的比特率(码流速率)、分辨率(传输大小)或上述各项的任意组合重新进行编码。从高质量的高清专业相机到低分辨率的智能电话录制,视频内容来源广泛;而视频内容接收器也是种类繁多,从大型的高清电视屏幕到低分辨率的手持终端,无所不包。视频基础局端必须全方位满足各种需求,其中包括:
- 多重编码和解码标准,如 DV、MPEG2/4、H.264 以及未来的 H.265 等。
- 多种分辨率和帧速率,从 128×96 像素的次 1/4 公用中分辨率格式 (SQCIF) 乃至更低分辨率,到高清 (1920x1080) 甚至是超高清 (4320P, 8K),从每秒 10 帧到每秒 60 帧不等。
- 各种编码的输入/输出 (I/O) 比特率,如从低分辨率低质量手持终端视频流的 48 Kbps 到专业质量的 50 Mbps(H.264 级 4.2)甚至更高。YUV域视频流的带宽要求非常高,例如,采用 4:2:0 配色方案的 YUV 1080p60 视频流需要 1.5 Gbps 左右的带宽。
延迟要求因应用而异:视频会议和实时游戏应用对延迟的要求非常严格,不能超过 100 毫秒;视频点播应用则可以接受中等延迟(可达几秒钟),而且存储等非实时应用的处理能够允许更长时间的延迟。
通信基础局端网络面临的挑战在于,如何才能够将所有的内容交付给所有所需用户,同时又能维持硬件资源的高利用率和高效性。为了进一步阐述这一挑战,不妨考虑一下这个事实,单个 1080i60 通道要求的处理负载与 164 个帧速率为 15 fps(假定负载与分辨率和帧数量之间呈线性关系)的 1/4 公用中分辨率格式 (QCIF)的通道相同。因此,支持单个 1080i60通道的硬件也应该能够以同等的高效性和高利用率支持 164 个 QCIF 通道。但是,以如此数量级实现的可扩展性是一大挑战。
为了符合高可扩展性要求,必须采用可编程的硬件解决方案。部分视频应用要求处理器具有极高比特率的信号输入与输出,因此,基于处理器的解决方案必须拥有可支持足够外部接口的理想外设。这种处理器必须具备足够的处理能力,可处理实时的高清高质量视频,同时还需配备足够的本机资源,如快速存储器、内部总线和 DMA 支持等,以使处理器的处理能力获得高效利用。
单内核 DSP 具有高度的灵活,能够高效执行各种算法。DSP 不仅能够处理话音、音频、视频,还可以执行其他功能。但是,由于单内核 DSP 的计算能力不足,因而不能自由地处理任何分辨率的实时视频,而只能处理 SQCIF、QCIF 以及公用中分辨率格式 (CIF) 等较低分辨率的视频;而且,单内核 DSP 的功耗也使其无法应用在高密度视频处理系统中。
新型的多内核 DSP 具备非常高的处理能力,且其每次运行的功耗也比单内核 DSP 低。为了确定多内核处理器对于通信基础局端而言是否能够成为有效的硬件解决方案,需要对其接口、处理性能、存储器要求以及多内核合作与同步机制针对各种不同的使用案例进行符合性验证。
2.1 外部 I/O 接口
典型转码应用的比特流是以 IP 数据包形式进行打包。转码应用所需的带宽与分辨率以及用户所需网络的可用带宽相关。以下针对单通道消费类质量 H.264 编码视频流作为分辨率函数时列出的公用带宽要求:
- HD 分辨率,720p 或 1080i - 6 至 10 Mbps
- D1 分辨率,720×480,30 帧/秒 (fps),或 720×576,25 帧/秒 – 1 至 3 Mbps
- CIF 分辨率,352×288,30 帧/秒 – 300 至 768 Kbps
- QCIF 分辨率,176×144,15 帧/秒 – 64 至 256 Kbps
转码应用所需的总外部接口是输入媒体流与输出媒体流所需带宽的总和。为了支持多个 HD 分辨率通道或大量较低分辨率通道,至少需要一个串行千兆位介质独立接口 (SGMII)。
非转码视频应用涉及从 YUV(或同等)域对原始视频媒体流进行编码或解码。原始视频流具有较高的比特率,且通常通过 PCI、PCI Express 或串行快速输入/输出 (SRIO) 等高比特率的快速多通道总线直接从处理器输入或输出信号。
以下列出了使用 8 位像素数据和 4:2:0 或 4:1:1 配色方案传输 YUV 域中单通道原始视频流所需的带宽:
- 1080i60 - 745.496 Mbps
- 720p60 - 663.552 Mbps
- D1(30fps NTSC 或 25 fps PAL)- 124.415 Mbps
- CIF(30 fps)- 36.49536 Mbps
- QCIF(15 fps)- 4.56192 Mbps
因此,可对 4 个 1080i60 H.264 通道进行解码的处理器要求能够支持超过 4 Gbps 速率的总线,从而可假定总线的利用率为 60%。
2.2 处理性能
在可编程处理器的 H.264 通道上进行视频处理所需的处理性能取决于众多参数,其中包括分辨率、比特率、影像质量以及视频剪辑内容等。本章不仅将讨论影响周期消耗的因素,而且还将给出普通应用实例平均周期消耗的经验法则。
与其他视频标准一样,H.264 仅定义解码器算法。对于既定编码媒体流而言,所有的解码器都可生成相同的 YUV 视频域数据。
因此,解码器不决定影像质量,而由编码器决定。不过,编码器质量能影响解码器的周期消耗。
熵解码器的周期消耗取决于熵解码器的类型和比特率。H.264 MP/HP 为熵解码器定义了两种无损算法,即上下文环境自适应二进制算术编码 (CABAC) 和上下文环境自适应可变长度编码 (CAVLC)。CABAC 能提供更高的压缩比,因此,比特数相同时影像质量会更佳,但相比 CAVLC 在每个媒体流比特上约多消耗 25% 的周期。用于解码 CABAC 或者 CAVLC 媒体流所需的周期量是比特数的一个非线性单调函数。
所有其他解码器功能的处理负载均是分辨率的函数。更高分辨率需要更多的周期,几乎与宏模块的总数量呈线性关系。视频流内容、编码器算法与工具能在一定程度上影响解码器的周期消耗。附录 A – 解码器性能依赖性 (Decoder Performance Dependency) 列举了可能会影响解码器周期消耗的编码器算法和工具。
在可编程器件上实施既定比特率的编码器需要在质量与处理负载之间进行权衡。附录 B – 运动估算与比特率控制 分析了可能影响编码器质量并消耗大量周期的两种编码器算法。
对于典型的运动消费类电子设备的高质量视频流而言,以下列表给出的经验法则,可用以判断常见使用案例中 H.264 编码器消耗的周期数。
- QCIF 分辨率、15 fps、128 Kbps - 每通道 2,700 万个周期
- CIF 分辨率、30 fps、300 Kbps – 每通道 2 亿个周期
- D1 分辨率、NTSC 或 PAL、2 Mbps –每通道 6.6 亿个周期
- 720p 分辨率、30 fps、6 Mbps – 每通道 18.5 亿个周期
- 1080i60、每秒 60 场、9 Mbps – 每通道 34.5 亿个周期
与此类似,H.264 解码器消耗的周期数为:
- QCIF 分辨率、15 fps、128IKbps – 每通道 1400 万个周期
- CIF 分辨率、30 fps、300 Kbps – 每通道 7050 万个周期
- D1 分辨率、NTSC 或 PAL、2 Mbps –每通道 2.92 亿个周期
- 720p 分辨率、30 fps、6 Mbps – 每通道 7.8 亿个周期
- 1080i60、每秒 60 场、9 Mbps –每通道 16.6 亿个周期
转码应用(包括完整的解码器和编码器)消耗的周期数是编码器和解码器所消耗的总和,在需要的情况下也会加上扩展的消耗。
2.3 存储器的考虑事项
在成本与存储器要求之间进行权衡折中是任何硬件设计都需要考虑的重要因素。在分析多核视频处理解决方案的存储器要求时,需要明确以下几个问题:
- 需要多大存储量的存储器,以及存储器的类型(专有还是共享)是什么?
- 存储器的速度是否足够支持流量需求?
- 接入总线的速度是否足以支持流量需求?
- 存储器架构是否能够以最少的多核性能损失支持多核接入?
- 存储器架构是否能以最小的数据冲突支持处理器数据流的输入与输出?
- 支持存储器接入(诸如 DMA 通道、DMA 控制器、预取机制和快速智能高速缓冲架构 )的现有硬件有哪些?所需存储器的存储量取决于应用。以下三个应用实例介绍了三种不同的存储器要求:
无线传输速率:在单帧运动估算参考 (single-motion estimation reference frame) 中以极低的延迟从 QCIF H.264BP 转换至 QCIF H.264BP 需要足够的存储容量才能存储 5 个帧。每帧需要 38016 个字节,那么一个通道(包括输入和输出媒体流的存储)所需存储器的存储量为每通道不足 256KB。同时处理 200 个通道则需 50MB 的数据存储。
多通道解码器应用实例:对于 H264 HP 1080p 解码器,如果两个连续的 P 帧和 I 帧之间的 B 帧数目等于或少于 5,那么我们只需要足够存储 7~8 个帧的存储空间,因而单个通道(包含存储输入和输出媒体流)所需的存储量应少于每通道 25MB。同时处理 5 个通道需要 125MB 的数据存储器。
包含实时电视广播的高质量视频流示例:应 FCC 的要求在系统中有 7 秒的延迟时,对实时电视节目采用 H.264HP 720P60 编码需要每个通道存储 600MB。并行处理两个通道需要 1.2GB 的数据存储量。
为了最大限度地提高视频处理系统的低成本优势,数据必须驻留在外部存储器中,其大小需要根据系统存储器最差的应用状态来选择。与此同时,处理过的数据必须存放在内部存储器中才能支持处理器的高吞吐量。优化的系统会使用乒乓机制将数据从外部存储器移至内部存储器,而将数据从内存移至外部存储器的同时还要处理来自内部存储器的数据。典型的处理器具有一个可配置为高速缓存或 RAM 的小型 L1 存储器,用于每个内核(可配置为高速缓存或 RAM)的较大型专用 L2 存储器,以及处理器中每个内核都能够存取的共享 L2 存储器均可使用。为加强乒乓机制,需要用多个相互独立的 DMA 通道从外部存储器中读写数据。
附录C 外部存储器带宽-为支持乒乓机制用于上述三个应用实例,估算了将数据从外部存储器移至内部存储器所需的带宽。外部存储器的有效带宽必须大于 3.5Gbps。

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码