TMS320DM6446构成的H.264编码器必威娱乐平台
2003年发布的H.264视频压缩编码标准在一定程度上解决了要在尽可能低的码率下获得尽可能好的图像质量这一问题。在相同的重建图像质量下,H.264能够比H.263节约50%左右的比特率,此外H.264还增强了其对网络的适应性,差错的恢复能力,使其非常适用于数字视频存储、IPTV及手机电视等视频质量要求高而信道传输环境不稳定的场合。
由于加入了多模式位移估计、基于4×4块的整数变换等多种新的算法,使H.264算法本身的复杂度大幅增加。因此本文采用基于TI的TMS320DM6446的DAVINCI_EVM平台作为算法的硬件平台,提出针对达芬奇平台对H.264编码器进行优化,在不降低编码质量的情况下提高程序运行效率,降低运算复杂度的一个实现方案。
H.264编码器的算法流程
H.264编码器结构如图1所示,输入的Fn为当前帧或场,编码器以宏块为单位进行处理,每个宏块可以选择帧内或者帧间预测两种编码方式。如果采用帧内编码模式,其预测值PRED(图中为P)是由本帧之前已经经过编码、解码、重建的一些样本点生成。而如果采用帧间模式,则P由一个或者多个参考帧的运动补偿预测生成。预测值P和当前块相减后,产生一个残差块D,经块变换、量化后产生一组量化后的变换系数X,再经熵编码,与解码所需的一些信息一起组成一个压缩后的码流,经NAL供传输和存储用。
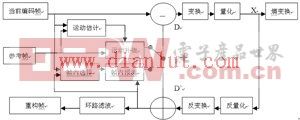
图1 H.264编码器结构
编码硬件平台概况
本文采用的达芬奇数字视频评估模块DVEVM(Digital Video Evaluation Module)是TI提供的用来评估DaVinci技术和DM644x体系架构的评估模块,是强调片上能力的一个很好的参考平台。其硬件资源包括TM320DM6446的DSP和ARM9的双核芯片、128MB的SDRAM、16MB的NAND Flash以及丰富的外设接口。
TM320DM6446中用于编码器具体实现的C64x+ DSP的时钟频率达到600MHz。C64x+ DSP的内部存储器的配置包括32KB的程序存储器L1P、80KB的数据存储器L1D和64KB的二级缓存L2。图2为TM320DM6446中DSP端的核心C64x+的结构原理图。
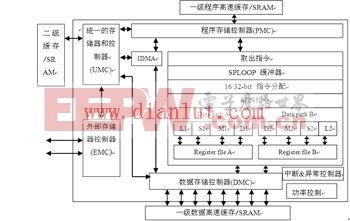
编图2 C64x+结构原理图
码器在TM320DM6446上的实现
由于DSP平台与PC平台的差异性,必须对PC上开发的编码器程序进行结构上的调整,并进行合理的内存分配才能在DSP平台上正常的运行。主要实现步骤如下。
1 编码器C语言结构调整
PC平台上用C语言实现的编码器在DSP平台上的编码帧率(fps)非常低,平均2秒才能编完一帧,其主要原因是无法利用DSP的并行处理机制。因此针对C64x+的特点,将程序中对流水线操作影响较大的的循环拆分成若干小循环实现。对编码器运行速度影响较大的模块如sad的计算,DCT变换等采用CCS自带的图像库以提高编码效率。
2 DSP端的内存配置
由于视频编码的数据存取量较大,而 DAVINCI_EVM提供了256MB的外部存储器DDR2,因此通过对DSP/BIOS的设置将外部存储器设置为DDR2,并将可执行的C代码及C代码的堆存入外部存储器中。
3 对DSP端的BOOT的设置
由于TM320DM6446采用双核的设计,ARM端只负责对整个工程的控制而不参与编码算法的具体实现。为了保证编码算法能在DSP端无中断的全速运行,需要对ARM端进行屏蔽,并通过对DAVINCI_EVM跳线的设置使DSP端自BOOT。
通过以上步骤编码器效率虽然有所提高,但仍无法满足实时性的要求,因此必须结合DM6446本身的特点对编码器算法进行进一步的优化。
编码器的优化
本文对H.264算法的优化主要有两个方面:1)对算法中耗时较多的运动估计模块进行优化。2)对DSP的数据搬移进行优化。
1 对编码器算法运动估计模块的优化
由于DSP硬件资源有限,因此有必要对H.264编码器中所耗时间较多的模块进行优化,表1为H.264各模块复杂度比较。
由表1可见运动估计占了一半左右的时间,运动估计复杂度高的主要原因是采用了全搜索算法,虽然精度非常高,但带来了大量的计算量。针对这一问题,本文在已有的快速算法菱形搜索算法基础上进行进一步的优化。

为了减少静止宏块被编码以及大模板搜索所带来的运算量,首先在用菱形算法进行运动搜索之前以待编码宏块周围已编码宏块的运动矢量信息及SKIP状况为依据预测当前宏块是否使用SKIP模式编码。当待编码宏块为非静止宏块时,再根据周围已编码宏块的SAD值预测当前宏块的运动剧烈程度,若是运动平缓的宏块则直接使用小模板进行搜索。只有当待编码宏块被判定为剧烈运动的宏块时才进行大模板搜索。由于多次的大模板搜索循环带来较大的计算量,因此在进行大模板搜索之前首先根据周围宏块的信息对最大搜索次数MaxNum进行预估值,当大模板的搜索次数大于MaxNum时直接跳转至小模板搜索。此流程设计可使静止宏块和运动平缓的宏块不进入运算量大的大模板搜索环节。优化后的菱形算法的流程如图3所示。
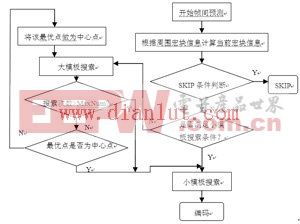
图3 优化算法流程图
2 对DSP数据搬移的优化
视频编码需要处理较大的数据量,如一帧CIF格式的YUV数据约有150KB,而H.264除了要存储当前帧的信息外还必须存储重建帧和参考帧的信息,为此必须使用DM6446的片外存储器,也即DDR。但是DSP的CPU对不同的存储器的访问速度是不一样的,访问速度最快的是离DSP核最近的L1P和L1D,其次是二级缓存L2,访问速度最慢的是DSP的片外存储器。DSP对不同的存储器的访问速度相差数倍。为了提高编码器的运行效率,节省DSP核对各个模块访问所消耗的时钟周期,需要启用DSP的DMA作为数据在两个存储器之间的传输通路。DMA的的特点是可以在不需要CPU干预的情况下,在后台执行数据的高速传输,能够有效减轻CPU的负荷。
C64x+在外部存储器与内部存储器之间的数据传递可以通过增强型DMA(EDMA)实现。EDMA传输的发起方式有三种,包括手动触发方式、外设事件发起方式及QDMA模式。在编码算法中,每处理完一组宏块就要向CPU提出DMA传输申请,因此采用QDMA模式的传输发起方式更适用于编码算法。
DSP核对两级内部存储器L1和L2的访问速度也不同,如果将外部存储器的数据直接通过EDMA传入L1D和L1P,这样的传输方式虽然较快,但需要分配比较大的L1 SRAM,这意味着L1的Cache就会变小,过小的L1 Cache会影响L2和外部内存中的代码和数据的效率。出于上述考虑可以将L2作为L1与外部存储器之间的数据过渡区。L1和L2之间的数据传递采用C64x+新引入的IDMA,其原理跟EDMA相似,实现两个内部存储器的高速数据传递。
为了使EDMA可以不间断的实现数据的搬移,本文采用了二级乒乓传输的方式,首先在L1 SRAM和L2 SRAM中开辟两个缓冲区,CPU在处理一个当前宏块组数据之前先处理EDMA和IDMA的传输申请,当CPU编码完一个宏块组时IDMA已将数据搬移至离核最近的L1缓冲区,当CPU继续处理下一个宏块组前再次处理EDMA和IDMA的传输申请。如此以乒乓传递的方式搬移数据可以保证CPU处理数据时最短的等待时间。图4为L1、L2及外部存储器DDR2之间的数据传入示意图。
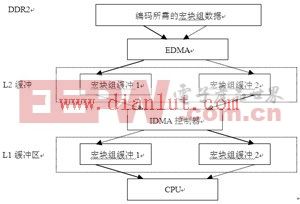
图4 存储器数据传递流程图
3 优化结果及分析
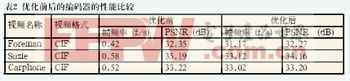
表2为优化前后的H.264编码器对三个测试序列在DM6446上编码后的结果比较。在表2中,优化后的帧频率比优化前有了较大幅度的提高,这是由于对编码器的运动估计模块进行优化后,有效减少了这一模块所消耗的时钟周期。而对DSP数据搬移方式的优化,减少了DSP核等待数据搬入所消耗的时钟周期。表中PSNR的值在优化前后并没有明显变化,说明优化后编码质量未受大的影响。
结束语
本文结合DM6446的硬件结构特点,将H.264编码器在DM6446中成功实现,并对编码器运动估计模块及DSP在编码时的数据搬移进行了优化,取得了初步的效果,基本可达到CIF格式序列的实时编码要求。由于DM6446具有DSP和ARM9的双核构架,ARM端负责对整个视频解决方案的控制和对编码算法的调用,因此,下一步的工作重点为实现在ARM端对优化后的编码算法进行合理的调用和控制。

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码