如何使用最大似然检测器方案优化MIMO接收器性能
MIMO的规格取决于发送和接收天线的数量。在一个4×4 MIMO配置中,使用了四个发送天线和四个接收天线。这在同样信道带宽上实现了(在合适的条件下)高达四倍的数据传输。
一方面,简单的MIMO接收器基于线性接收器算法,其易于实现但无法完全利用MIMO的好处。另一方面,使用迭代法,可以实现最佳的最大后验概率近似MIMO算法;然而,这会导致高延时的不足。一种更加实用的非线性MIMO接收器的实施途径是最大似然(Maximum Likelihood, ML)或最大似然检测器(Maximum Likelihood Detector, MLD),它在根本上是基于一个彻底的并列搜索。MLD在处理方面比传统线性接收器要求更高,但对于相同的信道条件,可提供明显更高的比特率。另外,对于具有天线相关性的信道,MLD更稳健可靠。
使用高阶MIMO规格(超过两个接收和两个发送天线)可以导致显著的频谱效率改进——但这也有其成本代价:随着MIMO规格的增加,MLD接收器的计算复杂性以指数方式增加。高阶MIMO要求相当大的处理能力——对于这一点,直接的MLD方法是不切实际的,必须使用次优(suboptimal)MLD算法来实现用户设备(User Equipment,UE)的实施。
次优ML接收器
次优ML接收器试图以更有效的方法来扫描可能的传送信号,从而减少整体复杂性并达到接近ML精度的结果。减少复杂性有助于根据大小和功率进行更加实际的硬件实施。这还使硬件能够保持由先进通信标准规定的高吞吐量。
次优ML方程式的解决可定义为一种树形搜索,其中树的每一个层级对应于一个发送符号。每个节点的分支突出数匹配QAM或发送符号的调制。一个4×4 MIMO配置可由一个四层树表示。假如调制为BPSK,每个节点将包含两个分支。
一旦定义了树的符号,可以部署树遍历算法,借用其它领域比如计算机科学。
关于此点,次优ML接收器可划分为两个主要类型:
1.横向优先搜索
2.深度优先搜索
横向优先搜索
横向优先的一个例子就是K-best算法。该解码器是一个固定复杂性解决方案,从树根开始并上行,直至它达到树的最后一层。在树的每层上,对所有选择的分支进行了评估并保留K留存节点,匹配最佳解决方案(代表了最接近接收信号的符号)——因此得名“K-best”。K剩余树叶然后就用于生成LLR结果。
该解码器的优点是:
*单向流有助于硬件的简易流水线实施。
*计算每层所需要的处理能力是恒定的,且直接与实施中所选的留存节点(K)的数量相关。
*数据吞吐量是恒定的,其反过来简化了在系统中计划的数据流
该解码器的缺点包括:
*需要大面积实施以便评估和分类所有选择的层级节点。
*精度要求越高,所需要的K值越高。
*在最佳SNR条件中,数据吞吐量不会增加。
*不能保证达到ML解决方案,因为最佳解决方案可能存在于没有选择的节点中。
下述图表显示了一个采用QPSK调制的MIMO 4×4 (4-层)树。在此例子中,K为四。树的每层将分为十六个节点。最好的四个将会是用于下一层的留存节点。
深度优先搜索
深度优先的一个例子就是软输出球解码(Soft-Output Sphere Decoder)算法。此解码器是一种自适应复杂性解决方案,从树根开始并首先直接上升到树叶——因此得名“深度优先”。该树的优先解决方案确定了初始搜索半径或范围。从那时起,解码器在整个树层中追溯并上升。对树的每个超出搜索半径的节点及其下面的所有节点进行修整。每次找到一个更好的解决方案,相应地减少半径范围。以此方法,扫描并修整了符号树,直至有效选项数量减少。余下的符号代表了ML解决方案。
此解码器的优点是:
*可保证获得ML解决方案,有助于结果精确度。
*在高SNR条件下,解码器运行更快,增加了数据吞吐量并降低了功耗。
*相比同等的横向优先解决方案,可在更小区域内实施。
图3显示了具有自适应复杂性软输出球解码器与固定复杂性K-best解码器间的循环计数比较。因为SNR增加,球解码器将减少它的循环计数,而固定复杂性将保持不变,无论信道条件如何。
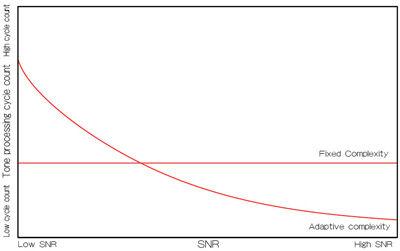
图3:固定对自适应复杂性。
该解码器的缺点包括:
*解码器的非确定性表现使系统计划复杂化。
*仅在当前分支完成后才知道下一个分支选择。这使得硬件传递途径的实施受到挑战。
图4显示了一个采用QPSK调制的MIMO 4×4 (4层)树例子。
1.深度优先以下列方式选择到第一个树叶的符号路径:a. -3 (层1);b. -3 (层2);c. 1 (层3);d. 3 (层4)
2.更新了初始半径
3.追溯执行到第二层的一个符号
4.在搜索期间,修整了超出搜索半径的分支(红色所示),因此使搜索树最小化。
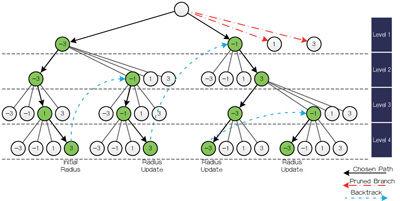
图4:球解码树遍历。
CEVA解决方案
CEVA通过推出最大似然MIMO检测器(MLD)来应对MIMO接收器的挑战。该MLD是紧密耦合扩展加速器硬件单元。该MLD能够处理LTE——先进的Cat.7数据流并产生软输出最大对数解决方案。
该MLD加速器达到了次优最大似然(ML)解决方案,可用于4×4或3×3 MIMO @12.6 Mega-tones/秒,使用软输出球解码器方法,以及2×2基于LORD的ML解决方案@ 28.8 Mega-tones/秒,使用载波聚合。该MLD设计用于移动应用,强调低功耗设计理念。
功能集
MLD功能集包括对以下的支持:
*从2×2到4×4 MIMO的可变传输模式,且每层可配置的调制高达64QAM.
*三种搜索优化:每个树层的用户自定义层排序,初始半径和搜索半径。
*通过提供吞吐量控制能力,CEVA MLD解决了软输出球解码的非确定性质,包括用于音调处理的上下循环计数界线。另外,使用用户自定义的基于时间标记的终端来保持系统吞吐量。
*可以扩展软比特来补偿SNR和调制因数。
*在内部符号和内层解决方案中提供对LLR排列的支持
*内层解映射:支持两个代码层,使MLD能够将所写数据拆分到两个不同的目的地。
*可扩展的硬件解决方案实现了性能/功率/面积的权衡,包括选择MLD引擎的数量、缓冲器大小和接口时钟比率。
另外,加速器提供了广泛的调试和性能分析能力。
MLD加速器方框图
图5描述了MLD加速器的方框图,其包含了一个AXI接口、输入缓冲器、分配器、最大似然引擎(Maximum Likelihood Engine,MLE)、LLR发生器、重排序缓冲器和输出缓冲器。
输入缓冲器存储了大量的音调数据,通过分配器,每次传送一个音调到MLE.每个MLE输出有关检测到的比特数据;这进而通过LLR发生器转化为LLR格式。重排序缓冲器积累LLR数据,以便传输和发送有序的输出到输出缓冲器中。输出缓冲器通过AXI接口将LLR写到接收链中的下一个模块。
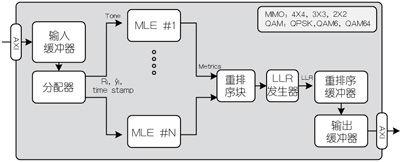
图5:MLD加速器方框图。
MLD性能
图6描述了与MMSE接收器相比较的CEVA MLD TCE的性能,使用了4×4空间复用MIMO.封包出错率中的吞吐量可在不同的SNR条件下评估。LTE信道设置在EPA 5Hz和低相关传播条件上。
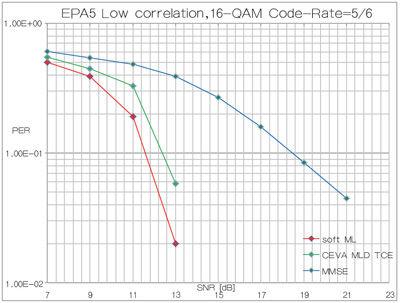
图6:4×4 MIMO空间复用性能。
CEVA的解决方案获得接近ML的结果,而MMSE遭受严重的性能下降,即便在低相关条件下。对于更高的相关条件,MMSE将会进一步恶化。
相比之下,具有类似性能的K-best解决方案将需要超过两倍的CEVA MLD TCE范围。
CEVA MLD TCE包含了:
*相比单纯的ML解码,MIMO 4×4具有低于1.5dB损失的极佳精确度。
*无精度损失解码MIMO 2×2 (LORD同等性能和复杂性)。
*超低功耗设计。
*有竞争力的芯片尺寸。
图7描述了4×4 MIMO的性能,采用64-QAM调制,SM在最高编码速率下。即使在这些条件下,相比理想的ML结果,CEVA MLD TCE仍提供了低于1.5dB的精度损失。
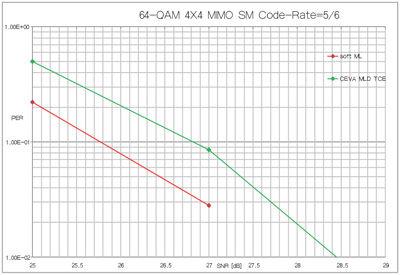
图7:MLD 4×4 MIMO的性能。
图8说明了SM在最高编码速率下的2×2 MIMO的性能,采用64-QAM调制。CEVA MLD TCE提供完美的ML性能。
结论
本文展示MLD接收器实现了优于线性接收器的结果,但当选择MLD实施时,仍有许多因素需要考虑。MLD接收器设计人员必须选择最合适的解决方案用于所需的应用,要考虑以下因素:
*精度目标和吞吐量要求:需要一个用户可配置的解决方案,以便快速获得高质量LLR.
*延迟定义:需要可定义的系统计划,以便在规定的时间内完成任务——例如,通过使用时间标记。
*信道类型快/慢时间变化:快速时间变化信道将需要频繁更新信道信息的能力。
*硬件考虑:大小、速度(MHz)和功耗。
*需要可扩展的硬件解决方案来满足小面积和低功耗需求。

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码