使用Theano,Python,PYNQ和Zynq开发定点Deep Recurrent神经网络
可编程逻辑(PLD)是由一种通用的集成电路产生的,逻辑功能按照用户对器件编程来确定,用户可以自行编程把数字系统集成在PLD中。经过多年的发展,可编程逻辑器件由70年代的可编程逻辑阵列器件 (PLD) 发展到目前的拥有数千万门的现场可编程阵列逻辑 (FPGA),随着人工智能研究的火热发展,FPGA的并行性已经在一些实时性很高的神经网络计算任务中得到应用。由于在FPGA上实现浮点数会耗费很多硬件资源,而定点数虽然精度有限,但是对于不同应用通过选择合适的字长精度仍可以保证收敛,且速度要比浮点数表示更快而且资源耗费更少,已经使其成为嵌入式AI和机器学习应用程序的理想选择。
最新的证明点是英国伯明翰大学电子电气和系统工程系的Yufeng Hao和Steven Quigley最近发表的论文。论文标题为“在Xilinx FPGA上实现深度递归神经网络语言模型“,介绍了使用Python编程语言成功实现和训练基于固定点深度递归神经网络(DRNN); Theano数学库和多维数组的框架; 开源的基于Python的PYNQ开发环境; Digilent PYNQ-Z1开发板以及PYNQ-Z1板上的赛灵思Zynq Z-7020的片上系统SoC。Zynq-7000系列装载了双核ARM Cortex-A9处理器和28nm的Artix-7或Kintex-7可编程逻辑。在单片上集成了CPU,DSP以及ASSP,具备了关键分析和硬件加速能力以及混合信号功能,出色的性价比和最大的设计灵活性也是特点之一。使用Python DRNN硬件加速覆盖(一种赛灵思公司提出的硬件库,使用Python API在硬件逻辑和软件中建立连接并交换数据),两个合作者使用此设计为NLP(自然语言处理)应用程序实现了20GOPS(10亿次每秒)的处理吞吐量,优于早期基于FPGA的实现2.75倍到70.5倍。
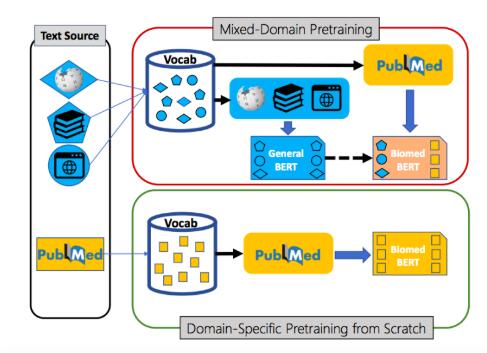
论文的大部分讨论了NLP和LM(语言模型),“它涉及机器翻译,语音搜索,语音标记和语音识别”。本文随后讨论了使用Vivado HLS开发工具和Verilog语言实现DRNN LM硬件加速器,可以为PYNQ开发环境合成一个定制的硬件覆盖。由此产生的加速器包含五个过程元素(PE),能够在此应用程序中提供20GOPS的数据吞吐量。以下是设计的框图:

DRNN加速器框图
Vivado设计套件为下一代超高效率的C/C++和基于IP的设计提供了新的方法。融入了新的超快高效率设计方法集,用户可以实现10-15倍的效率的提升。Vivado HLS支持ISE和Vivado设计环境,可以通过集成C,C++和SystemC标准到赛灵思的可编程器件中而无需创建RTL模型,加快IP的创建。
这篇论文中包括了大量深入的技术细节,但是这一句话总结了这篇博客文章的理由:“更重要的是,我们展示了软件和硬件联合设计和仿真过程在神经网络领域的应用“。考虑到PYNQ-Z1开发板的售价为229美元,这种说法是完全正确的。

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码