Nikko Strom揭秘语音识别技术:Alexa是怎样炼成的?
声学模型就是一个分类器(classifier),输入的是向量,输出的是语音类别的概率。这是一个典型的神经网络。底部是输入的信息,隐藏层将向量转化到最后一层里的音素概率。
这里是一个美式英语的 Alexa 语音识别系统,所以就会输出美式英语中的各个音素。在 Echo 初始发布的时候,我们录了几千个小时的美式英语语音来训练神经网络模型,这个成本是很高的。当然,世界上还有很多其它的语言,比如我们在2016年9月发行了德语版的Echo,如果再重头来一遍用几千个小时的德语语音来训练,成本是很高的。所以,这个神经网络模型一个有趣的地方就是可以“迁移学习”,你可以保持原有网络中其它层不变,只把最后的一层换成德语。
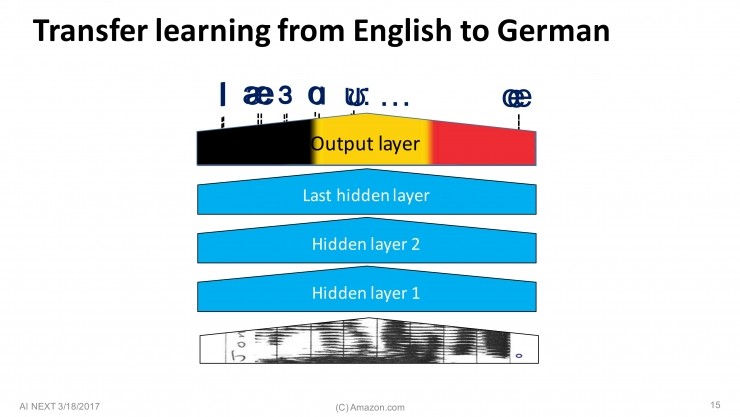
两种不同的语言,音素有很多是不一样的,但仍然有很多相同的部分。所以,你可以只使用少量的德语的训练数据,在稍作改变的模型上就可以最终得到不错的德语结果。
“锚定嵌入”
在一个充满很多人的空间里,Alexa 需要弄清楚到底谁在说话。开始的部分比较简单,用户说一句唤醒词“Alexa”,Echo上的对应方向的麦克风就会开启,但接下来的部分就比较困难了。比如,在一个鸡尾酒派对中,一个人说“Alexa,来一点爵士乐”,但如果他/她的旁边紧挨着同伴一起交谈,在很短的时间里都说话,那么要弄清楚到底是谁在发出指令就比较困难了。
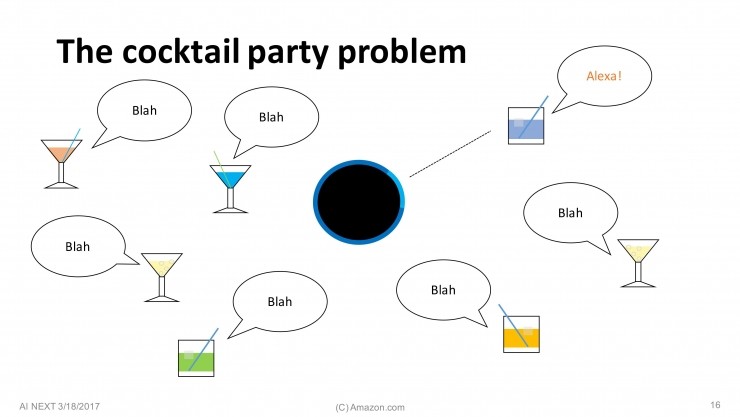
这个问题的解决方案来自于2016年的一份论文《锚定语音检测》(Anchored Speech Detection)。一开始,我们得到唤醒词“Alexa”,我们使用一个RNN从中提取一个“锚定嵌入”(Anchor embedding),这代表了唤醒词里包含语音特征。接下来,我们用了另一个不同的RNN,从后续的请求语句中提取语音特征,基于此得出一个端点决策。这就是我们解决鸡尾酒派对难题的方法。
“双连音片段”
Alexa里的语音合成技术,也用在了Polly里。语音合成的步骤一般包括:
第一步,将文本规范化。如果你还记得的话,这一步骤恰是对“语音识别”里的最后一个步骤的逆向操作。 第二步,把字素转换成音素,由此得到音素串。 第三步是关键的一步,也是最难的一步,就是将音素生成波形,也就是真正的声音。 最后,就可以把音频播放出来了。

Alexa拥有连续的语音合成。我们录下了数小时人的自然发音的音频,然后将其切割成非常小的片段,由此组成一个数据库。这些被切割的片段被称为“双连音片段”(Di-phone segment),双连音由一个音素的后半段和另一个音素的前半段组成,当最终把语音整合起来时,声音听起来的效果就比较好。
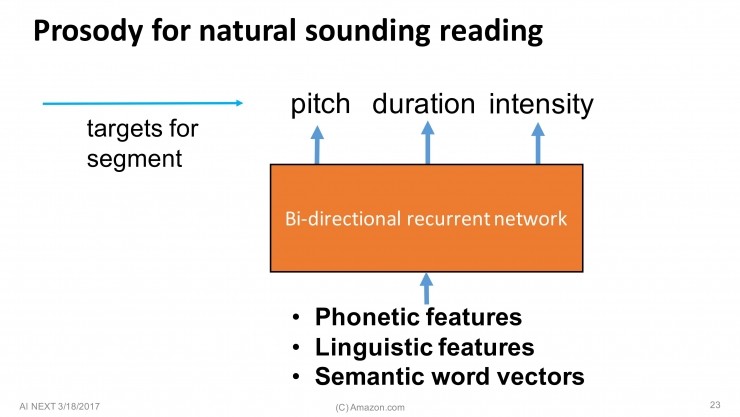
创建这个数据库时,要高度细致,保证整个数据库里片段的一致性。另外一个重要环节是算法方面的,如何选择最佳片段序列结合在一起形成最终的波形。首先要弄清楚目标函数是什么,来确保得到最合适的“双连音片段”,以及如何从庞大的数据库里搜索到这些片段。比如,我们会把这些片段标签上属性,我今天会谈到三个属性,分别是音高(pitch)、时长(duration)和密度(intensity),我们也要用RNN为这些特征找到目标值。之后,我们在数据库中,搜索到最佳片段组合序列,然后播放出来。

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码
相关文章
-
网络与存储 2023-12-07
-
2023-09-21
-
-
-
2022-03-10

-
-
2020-10-10

-