基于FPGA的DDR3多端口读写存储管理系统设计
5验证结果与分析
图形生成写中断处理仿真图如图10所示。由于图形生成数据不是从左往右连续进行的,因此每次突发写操作发送的128位数据(BL=8),有效的数据只有低16位,高112位直接用掩码屏蔽(app_wdf_mask=16‘hfffc)。当一帧图形全部绘制完成后发送图形生成模块写请求(graphics_done=1)。此时图形中断处理器执行直接结果写中断(graphics_wr_interrupt=1),视频中断处理器执行插值背景读中断(graphics_wr_interrupt_rd_bk=1)。当两者同时完成(rd_bk_video_finish=1)时,图形中断处理器执行插值结果写请求中断。其中,c0_app_XXX表示图形存储DDR3的用户接口,写图形数据时,用户接口地址系统和数据系统是对齐的;c1_app_XXX表示视频存储DDR3的用户接口,读视频背景时,数据系统比地址系统稍有延迟。
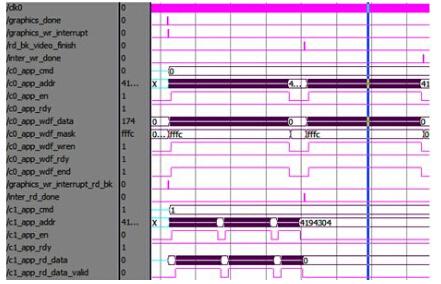
图10 图形生成写中断处理波形图
用本文设计的DDR3存储管理系统对文献[9]中图6.1进行中断处理。视频分辨率为1600×1200;绘制字符等直接结果点共812个像素(矩形填充忽略不算);绘制斜线等插值结果点共有4762个像素。用本文算法测试各中断处理时间如表2所示。
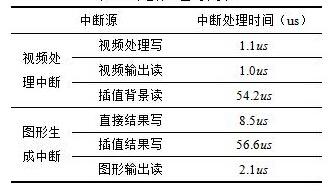
表2 中断处理时间表
视频中断处理器中,视频处理写中断将一行视频处理数据顺序写入到DDR3中耗时1.1us,则将一帧视频处理数据写入DDR3中耗时1.32ms;视频输出读中断从DDR3读出1行视频数据耗时1us,则将一帧视频读出需要1.2ms;插值背景读耗时54.2us.视频处理中断共耗时2.5742ms.图形处理中断中,图形输出读中断读出1行图形数据,并将其内存空间清零,共需要2.1us,即将一帧图形读出需要2.52ms,则图形处理中断共耗时2.5851ms.
与文献[9]结果相比,本文设计的系统对图形生成读写中断速度有了明显提高。因为文献[9]中断类型较多,且图形生成中断的优先级最低,在实现的过程中会多次被打断,导致图形生成执行时间较长;而本文算法中,插值背景读操作与直接结果写操作同时在视频中断处理和图形中断处理中进行,利用并行操作减少时间,并大大降低了复杂度。
结论
本文设计并实现了基于FPGA的DDR3多端口存储管理,主要包括DDR3存储器控制模块、DDR3用户接口仲裁控制模块和帧地址控制模块。DDR3存储器控制模块采用Xilinx公司的MIG方案,简化DDR3的逻辑控制;DDR3用户接口仲裁控制模块将图形和视频分别进行中断处理,提高了并行速度,同时简化仲裁控制;帧地址控制模块将DDR3空间进行划分,同时控制帧地址的切换。
经过分析,本文将图形和视频中断分开处理,简化多端口读写DDR3的复杂度,提高并行处理速度。

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码