基于Xtensa可配置处理器技术的视频加速引擎开发技术
掌上多媒体设备的增长极大地改变了终端多媒体芯片供应商对产品的定位需求。这些芯片提供商的IC设计目标不再仅仅针对一两种多媒体编解码器。消费者希望他们的移动设备能够利用不同的设备来播放媒体,能够采用不同的标准进行编码,并能够从不同的设备来下载或者接收媒体数据。视频译码器和编码器引擎必须满足多种需求,并具有面积和功耗优势。
1、设计视频加速引擎的传统RTL方法
上一代视频ASIC的设计主要对MPEG-2进行编码和译码,因为这是DVD标准。有些视频ASIC还支持MPEG-1,用于VCD(视频CD)播放。在多数情况下,MPEG-2编码器和译码器都采用RTL设计方法。一个典型MPEG-2视频ASIC体系结构如图1所示,其中包括由各个RTL模块构成的视频子系统、主控制器和片上存储器。
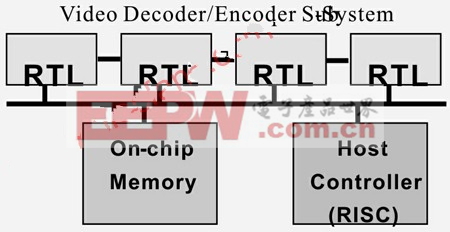
图1 MPEG-2视频ASIC体系结构
采用硬线RTL体系结构支持多种视频标准,然而,这也意味着每个视频标准都需要一个专用的RTL模块来实现。采用硬线RTL模块实现一个多种标准的视频加速引擎具有一定的局限性。无论是实现一个新的视频标准、更新已有的标准还是消除其中的故障都需要重新进行芯片加工。
2、采用处理器作为视频加速引擎的优势
可编程处理器能够满足多种视频标准的灵活性要求。与RTL模块设计方法相比,可编程处理器具有如下几个优势:一是易于将编解码器与处理器接口;二是满足新的视频标准要求、更新现有编解码器或者采用软件方法在芯片投片后也可以修改故障;三是可以采用软件更新的方法很容易地提高视频编解码器的性能。
然而,传统的32位处理器存在性能瓶颈,因为它们是面向通用代码设计的,而不是面向视频加速引擎设计的。嵌入式DSP也并非专门为视频量身定做的,而是包括硬件功能部件、指令和接口,专门应用于通用DSP领域。因此,为了在传统RISC和DSP处理器上实现视频编解码器,就必须使这些处理器运行在很高的速度(Mhz)上,需要大量的存储器空间,因此需要很大的功耗,不适合便携式应用。
通过研究一个视频内核程序所需要的计算量,即可一目了然。比如,一个绝对差值累加运算SAD,该运算是大部分视频编码算法中运动估计一步常采用的方法。SAD算法将会在相邻两个连续视频帧中找出宏块的运动情况,为此,需要计算两个宏块中每一组对应的像素值之间绝对差值的累加和。
下面C代码给出了SAD核心算法的简单实现:
for (row = 0; row numrows; row++) {
for (col = 0; col numcols; col++) {
accum += abs(macroblk1[row][col] - macroblk2[row][col]);
} /* column loop */
} /* row loop */
SAD核心算法的基本计算方法如图2所示。正像图中所示的那样,SAD核心算法首先执行减法操作,然后取绝对值,最后对前面的结果进行累加。
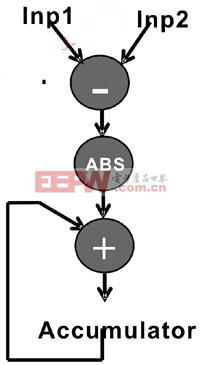
图2 差值绝对值累加(SAD)主要计算方法
在一个RISC处理器上计算一个由两个16x16宏块组成的SAD运算需要256次减法运算、256次绝对值运算和256次累加运算,共需要768次算术运算,这还不包括因数据转移需要的取数和存数操作。由于这需要对每一帧的所有宏块进行操作,因此,随着分辨率的提高引起视频帧增加,使得计算成本极度昂贵。
事实上,对于一个一般的通用RISC处理器而言(包括一些DSP指令,如乘法指令和乘累加指令),执行一个H.264基准译码算法需要250 MHz的性能(CIF分辨率),而执行一个H.264基准编码算法则需要超过1 GHz的性能(CIF分辨率)。完成上述运算,仅处理器内核就需要500mW的功耗,更不要说由访存和视频SOC的其它部件所用的功耗。
3、可配置处理器方法
在一个处理器上实现SAD核心算法的一个更加有效的途径是建立 “减法-绝对值-加法”专用指令。这将大大降低算术运算的开销,对一个16x16宏块而言,运算次数将从768次降为256次。而且,由于采用一个功能部件就可以实现多个简单算术运算的融合操作,因此上面的运算只需一个指令周期就可以完成,这相当于原来的256个周期。 用户不能往一个标准的32位RISC处理器中添加指令,但是,完全可以往一个可配置处理器中添加专用指令。可配置处理器允许设计人员从可配置选项菜单中选择相关配置命令来扩展处理器功能,包括增加专用指令、寄存器文件和接口等。
下面是现代可配置处理器(例如Tensilica公司的 Xtensa处理器)提供的配置和扩展选项,这对于传统的固定模式处理器而言是做不到的。
(i) 配置选项:选项菜单包括下面几项:
a. 设计人员需要或者不需要的指令。例如,16x16的乘法或者乘累加、移位、浮点指令等等。
b. 零开销循环、五级或者七级流水线、局部数据加载或者存储部件个数等。
c. 是否需要存储器保护、存储器地址转换或者存储器管理部件(MMU)
d. 包含或者不包含系统总线接口
e. 系统总线宽度和局部存储器接口宽度
f. 局部(紧密耦合)存储器大小和数量。
g. 中断数量及中断类型和中断优先级。
(ii) 扩展选项:增加设计人员自己定义的功能部件,包括:
a. 寄存器和寄存器文件。
b. 多周期、仲裁复杂指令功能部件。
c. 单指令流多数据流SIMD功能部件。
d. 将单发射处理器变为多发射处理器。
e. 用户定制接口,可以直接对数据通路进行读写操作,例如,类似GPIO(通用输入/输出)引脚的处理器内核端口或者引脚,用于扩展先进先出FIFO队列的队列接口(可以与其它逻辑或者处理器内核进行接口)。
配置选项的好处是让设计人员通过仅选择与其应用有关的选项,就可以构建一个规模适度的处理器,并能够满足其特定应用。扩展选项的好处是让设计人员根据应用定制处理器,包括建立专用指令、寄存器文件、功能部件和相关接口,用于加速系统应用算法的执行。

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码