非结构化海量网络数据处理技术研究
1.3 网络数据包个数多
为提高发包效率,使发包延迟时间尽可能小,将数据包在采集后快速的发送出去,ARCA公司的采集器规定每个数据包的大小在设计上不允许超过1 500 B。同时,现在的测试参数都是高采样率,在这样的测试系统条件下,一个网络数据包可记录的参数量非常有限,必然会产生惟一标示的单个网络数据包的个数激增。
1.4 网络数据包非结构化
网络数据包具有典型的非结构化。在采集器端,按照测试系统的配置采集参数,并形成网络数据包。对于交换机而言,单个网络数据包的到来和发送没有完整的规则。在记录器上记录的原始网络数据包数据,在数据包的排列顺序上是无序的,数据包的周期是不确定的。不能准确预测到下一个网络数据包到来的顺序和时间。
2 网络数据处理方法
针对以上网络数据包的特点:最新的网络数据包格式和记录格式,海量的原始数据,数目庞大的测试参数,典型的非结构化,以及上千万、上亿的单个网络数据包。根据飞行试验的特点,必须在尽可能短的时间内给出飞行试验的数据分析结果,以便试飞工程师安排接下来的飞行试验。
2.1 内存映射文件
内存映射文件,是由一个文件到一块内存的映射。WIN32提供了允许应用程序把文件映射到一个进程的函数(CreateFileMapping)。使用内存映射文件处理存储于磁盘上的文件时,将不必再对文件执行I/O操作,使得内存映射文件在处理大数据量的文件时能起到相当重要的作用。在处理飞行试验海量网络数据时,需不断地提取数据的,进行判断、跳过等文件操作。如果按照以往的文件指针模式去提取网络数据,在数据处理效率上有可能不能满足飞行试验海量网络数据处理的需求。针对快速读取海量原始网络数据,内存映射文件模式提供了解决方法。
2.2 时间矩阵同步分析算法
针对飞行试验原始网络数据,每个单独的网络数据包总是有时间标识的。这些时间标识在整个原始文件中又是无序存放的。飞行试验的科目所需要的数据往往存在于多个网络数据包中,这些网络数据包中的数据往往不会是同一时刻采集的,也就是说网络数据包的时间标识不会是同时刻的。针对网络数据包的这些特性,为快速进行网络数据包的时统分析,设计了时间矩阵同步分析算法。
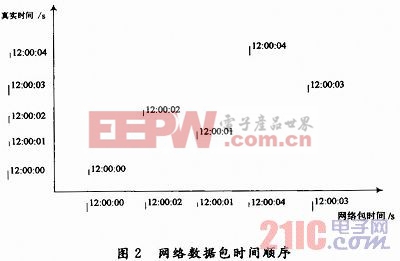
如图2网络数据包时间顺序所示,原始网络数据包的时间在顺序上是无序的。

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码