基于DM642的X.264编码器优化
(3)对全像素块运动预测搜索的方式,X.264默认为HEX(正六边形搜索半径为2),在对比测试了DIA(菱形搜索,半径为1)和UMH(可变半径六边形搜索)后,对比了速率和峰值信噪比后,发现在峰值信噪比相差很小的情况下DIA搜索速率最快,本文选择DIA作为运动预测搜索方式。表4给出3种方式的对比结果:

2.2 X.264代码优化
X.264编码器需要有效的利用DM642的特性,如软件流水,芯片特性和指令集等,才能有效的提高X.264编码器在DM642平台的编码效率。为了X.264能够充分的利用起DM642的特性,需要结合DM642本身的特点对移植过后的X.264代码进行优化,才能够提高X.264在DM642上执行的效率。
TI公司的DSP开发软件CCS提供了功能非常强大的编译器,编译工具可以对代码进行各种优化,以提高代码的执行速度,减小代码尺寸。这些优化包括了简化循环、软件流水、语句和表达式的顺序重排和分配变量到寄存器。利用CCS编译器进行优化后,仍然不能满足视频压缩的需求,需要继续对DM642上的X.264编码器进行优化。
(1)内联函数。内联函数是指用函数本身来代替函数调用这一过程。当调用内联函数时,C/C++源代码把此函数插入到调用点,而不采用传统的跳转。将函数设定为内联函数后,可以去掉复杂的函数调用过程来提高函数的执行效率,而付出的代价是增加了代码所占用的空间。使用关键字inline定义内联函数,在X.264编码器中的预测部分对其中一个频繁调用的函数设置为内联。代码如下:
static inline inI clip_uint8(int a)
(2)restrict关键字。为了帮助编译器确定存储器相关性,可以使用关键字restrict来限定指针、引用或数组。使用restrict关键字是为了确保其限定的指针在声明的范围内,是指向特定对象的惟一指针。编译器在读取函数的指针,数据时,采取保守的办法,认为它们是相关的。这时编译出的代码必须执行完前次写操作,才能开始下次读取操作。加入restrict关键字后,编译器将认为指针和数组没有相关性,能够并行提取数据。
(3)软件流水。软件流水式编排循环指令是能够使循环的多次迭代并行执行的技术。编译器总是力争使用软件流水技术。软件流水是DSP的关键技术,它利用的是算法中存在的指令并行性的特点,使一个循环的多次迭代同时进行。总地来说,当使用编译器优化的情况下,代码尺寸小,程序性能更优。x.264代码含有很多循环操作,故提高循环体指令的并行度使循环能够软件流水是提高编码效率的有效途径之一。
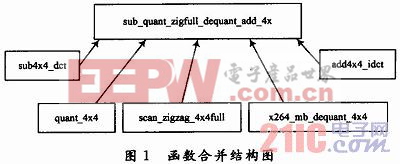
(4)函数合并。函数调用的过程中,要执行一些额外的寄存器。在编码过程中DCT、量化、zigzag、IDCT和反量化函数调用都非常频繁,但代码段都很短,部分代码只包含一个循环操作或者赋值操作。反复的调用会花费大量运行周期在函数调用上。为减少不必要的操作,提高速度,将DCT变换、量化、反量化和反DCT变化的整个过程进行优化,将几个函数合并到一个函数中。图1所示为合并结构。
2.3 DM642的优化
(1)CACHE优化。DM642采用了两级CACHE的存储器结构,两级CACHE主要用于对程序和数据的缓存。CPU直接和一级CACHE连接,一级CACHE包括L1P(程序)和L1D(数据),大小分别为16 KB,分别占用独立的存储;一级CACHE的存储速度与CPU处理速度相同。一级CACHE与二级CACHE相连,称为L2,大小为256 kB,可以对程序和数据进行统一存取,L2 CACHE作为L1CACHE和片外存储器之间的一个桥梁,可以由设计人员自行配置大小,分为SRAM和CACHE。L2CACHE的速度为CPU的一半。经过试验对比,将L2分为128 kBCACHE和128 kB SRAM。将部分调用比较频繁的函数和数据常量放在L2SRAM中,以提高读写速度。

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码