基于CMMB系统的LDPC译码器的设计与实现
2 CMMB中LDPC译码器的硬件实现
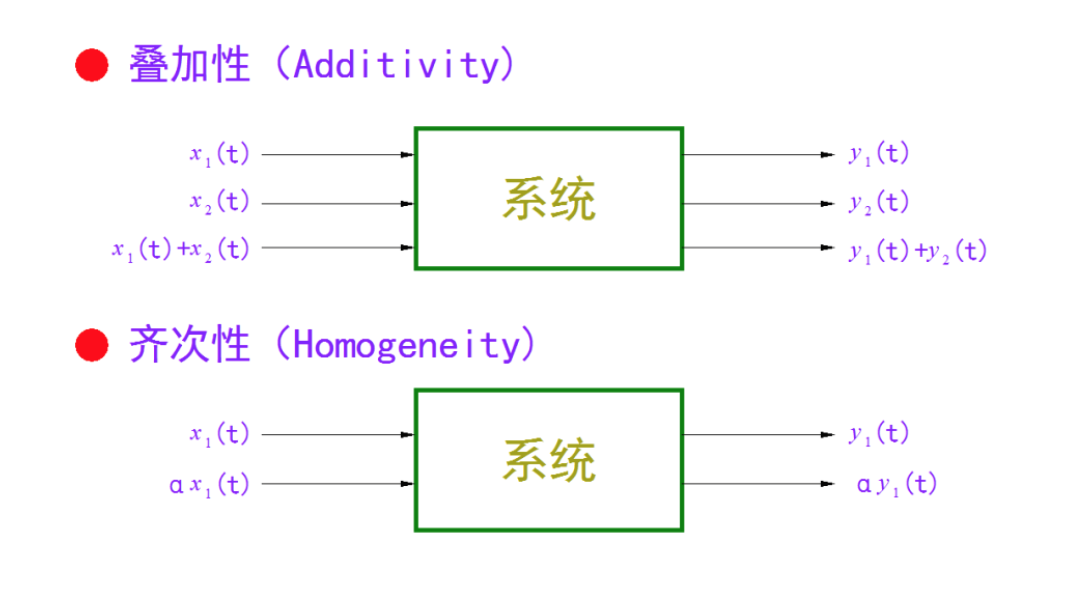
2.1 译码器总体结构
LDPC码的译码器通常有串行结构、并行结构和部分并行结构等。根据校验矩阵的特点,LDPC部分并行译码结构可简单分为输入和输出存储单元、VNU(变量节点运算)单元、CNU(校验节点运算)单元和中间结果存储单元。其译码器结构如图1所示。为了便于ASIC实现,本文采用单端口RAM,每块RAM由一个控制器控制以实现不同码率的地址初始化、读RAM、写RAM等操作。
2.2 输入和输出存储单元
检测到输入数据有效后,可把输入的串行数据依次存到初始化RAM里。本译码器一共有36个初始化存储器,每个存储器的深度为256。第1个数据存到第1个RAM的0地址,第2个数据存到第2个RAM的0地址,依次类推,第37个数据再存到第1个RAM的1地址,直到一帧9216个数据全部存满36个RAM。同样,输出存储单元可采用类似的存储器调度方式。为了实现译码的连续性,本设计在输入和输出部分使用了乒乓结构,即采用两组相同的36个RAM交替操作方式。
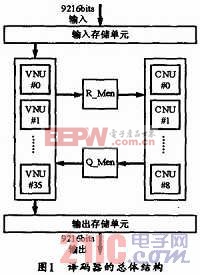
2.3 VNU单元
VNU单元用于完成两部分工作:一是由校验节点和初始化信息来更新变量节点的值;二是对每一列进行硬判决。检验节点更新后的值将存储到存储单元R_Mem,而硬判决后的比特值则存到输出存储单元,直到满足停止译码两个条件之一时才可输出码字。第一次垂直更新时,不用输入存储单元Q_Mem的值,而只把输入存储单元里的初始值送到VNU单元进行更新运算即可。由于两种码率下LDPC检验矩阵的列重都是3,因此,两种码率下的VNU个数都为36个,且每个VNU结构也都是4输入的VNU。每次运算时,都必须读输入存储单元和Q_Mem(除第一次迭代外)中的数据的运算结果,但应同时写入R_Mem存储单元中。本操作内部采用流水线结构,每次迭代都延迟2个时钟周期。由于读地址都为0,而且读地址每次加1,因此,执行变量节点更新运算共需花费256+2个时钟,垂直更新结构的变量节点单元加法运算器结构如图2所示。
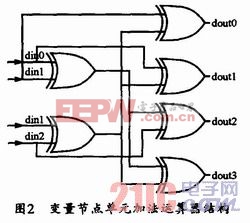
2.4 CNU单元
CNU单元也包括两部分工作:一是由变量节点来更新校验节点的值,并将更新后的值存储到外部存储器;二是对每一行硬判决后的比特进行校验,以确定其是否满足校验方程,也就是对每一行所对应比特进行异或,并看结果是否为零。若所有行的异或结构都为零,则译码成功,退出迭代。在CMMB标准中,两种码率校验矩阵H的行重有所不同(分别为6和12)。为了能共用CNU模块并且共享存储器资源,笔者设计了12输入的CNU单元,并且使用9个CNU单元并行计算。这样,当码率为1/2时,1个CNU单元更新2行,9个正好更新18行;而当码率为3/4时,9个CNU单元更新9行。每个12输入的CNU单元由2个6输入CNU单元组成,通过1个选择器可控制CNU输出。l/2码率时,2个6输入CNU的输出结果可直接作为12输入CNU的输出结果,然后经缓存后送入Q_Mem;3/4码率时,2个6输入CNU的输出再经过一级比较器得出的结果,才作为12输入CNU的输出值送到Q_Mem存储。为了方便比较最后一级比较器,可在复用已有的两组6输入输出比较单元的同时,还得输出两组最小值。CNU单元电路采用流水线结构来设计延时增加4个时钟周期(1/2码率)和5个时钟周期(3/4码率)。6输入输出CNU单元的结构简图如图3所示。

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码