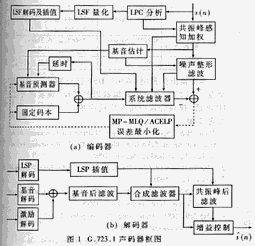
基于TMS320C6201的G.723.1多通道语音编解码的实现
3.1.2 提高寄存器的利用率
DSP芯片内部的运算单元运行效率非常高,但如果寄存器和数据总线之间的数据交换频繁,将使DSP的执行效率大打折扣。因为DSP在进行内存操作时,往往需要若干周期的延迟,如Load指令要有4个周期的延迟,Store指令需要2个周期的延迟。为了减少耗时的内存操作,可以在程序进入循环体之前,将要频繁使用的数据预先放入寄存器,然后反复调用,实践证明这种方法可以提高一部分效率。
3.1.3 使用内在函数(Intrinsic)
内在函数是在某些C6201DSP的汇编指令前加上“_”构成它可以方便地实现某些需若干C语句才能实现的功能。它是一种非常简便高效的优化方法,它的调用格式和普通C函数一样,但在编译时编译器会自动将Intrinsic用对应的汇编指令替代。C6201指令集中绝大多数的运算逻辑指令都可以这样使用,比如饱和绝对值、饱和加、饱和减、饱和乘、两个字中的对应半字同时加或同时减、两个字中的对应半字同时乘或交叉乘、归一化及位操作等。经过此步优化后,大部分循环体都可以生成较为有效的流水内核(piplinedkernel)。用Intrinsic替代G.723.1原先的C代码,运算量下降为原来的1/10。
3.1.4 对算法的冗余部分合理精简
经过检查,发现ITU-T G.723.1的C代码存在冗余部分。象6.3k码率的MP-MLQ搜索模块中,只需要用到偶数位置的脉冲响应的自相关,所以对奇数位置的脉冲响应自相关计算可以省略。
另外,在G.723.1标准中存在大量的10阶FIR和10阶IIR滤波器运算,如编码部分的感知加权、零输入响应、解码部分综合滤波器和后滤波等,FIR和IIR的通用形式可以表示为:
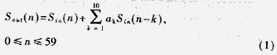
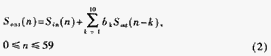
每次循环,FIR滤波器内存要用新的输入值更新,IIR滤波器内存要用新的输出值更新,使用按标准提供的算法,要专门用一个10阶循环更新内存。如果用一个10单位大小的循环缓存区,每次用新值覆盖最老的样值,动态调整循环缓存区的头指针,可以节省原先用于内存更新的cycle。
3.2 汇编级优化
由于C编译器只能完成70%的工作且对于复杂的循环,C编译器无法生成高效率的代码,所以对运算量大的模块只能用手写汇编。
3.2.1 字长优化
C6201的字长为32位,它支持按字节、半字、字存取。对于16位的数组,当它在内存中连续排列时,用32位读写指令LDW或STW替代16位读写指令LDH或STH,循环次数可减少一半。另外,C6201的汇编指令支持两个32位寄存器的高16位和低16位之间互乘,结果分别放到不同的寄存器中,互不影响。具体指令为SMPY(L×L)、SMPYH(H×H)、SMPYHL(H×L)和SMPYLH(L×H)。通过字长优化,可以大大提高程序的运行效率。必须注意的是,在使用字长优化时,数组在内存中的位置必须对齐32位边界。
3.2.2 对外循环的优化
C6201的C编译器对多重循环的最内层一般能较好地优化到一句到两句,但对外循环的优化效率则差很多。手写汇编时,可以先将内循环展开,再把外循环的指令并入其中,可以减少所耗费的cycle数。
C6201的循环一般分前导(Prolog)、内核(Kernel)及排空(Epilog)三部分。代码的并行程度从Prolog开始不断提高,Kernel内的并行程度最高,Epilog与Prolog相反,并行性逐渐降低。在多重循环中,如果尽量把内循环前导部分的指令与填入排空部分未用的单元,一起执行,可以在执行本次循环的排空语句的同时执行下次循环的前导语句。这样可不多花cycle而提高整个循环的效率。
4 实现结果
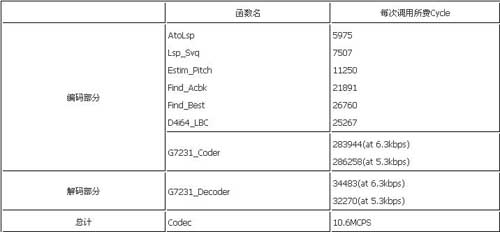
经过C语言级和汇编级的多种优化,最后实现了一路G.723.1的编解码需要花费10.6MCPS,整个代码的程序空间为208K byte(程序中包括了部分c6201的库函数),数据空间为8K byte,码本大小20k byte,多通道的上下文数据为1.48K byte。200MHz的C6201每秒可以实时编解码16路语音信号。所有代码全部通过了ITU-T测试矢量的测试。表1是各主要模块的运算量。
表1 G.723.1各主要模块运算量
本文提出的利用C6201 DSP进行ITU-T G.723.1全双工实时多通道语音编解码的实现。该实现可以在IP电话、视频会议中得到广泛应用。

加入微信
获取电子行业最新资讯
搜索微信公众号:EEPW
或用微信扫描左侧二维码